CyberTraining Workshop 2024: Emergency Evacuation Simulation with CyberGIS-Compute¶
Author: Rebecca Vandewalle rcv3@illinois.edu
Created: 6-15-24
This notebook provides an example of running an emergency evacuation simulation on a remote computing resource using CyberGIS-Compute. While this example will run on Virtual Roger (Keeling), a supercomputer at the University of Illinois, CyberGIS-Compute supports additional computing resources such as ACCESS (formerly XSEDE).
Overview: Running Code on CyberGIS-Compute¶
CyberGIS-Compute is a service for running High Performance Computing (HPC) jobs from a Jupyter Notebook. In this example, the emergency evacuation simulation is run twice, each separately using two different tasks on the supercomputer. This small example demonstrates how to run a serial script with no in-built parallelization multiple times on CyberGIS-Compute, how to pass parameters from a notebook to CyberGIS-Compute, how to access standard HPC variables (such as node_ids) from within a CyberGIS-Compute job, and how to specify the correct working and results directories for running the job script and downloading the results. The goal of this example is to demonstrate how to use CyberGIS-Compute with no or very little adjustments to the original serial script. The custom job in this notebook uses this repository: https://github.com/cybergis/cybergis-compute-fireabm.git .
Learning Objectives¶
- Learn how to run an emergency evacuation simulation using Python from within a Jupyter Notebook
- Learn how to use the CyberGIS-Compute graphic user interface to run code remotely on a High Performance Computing (HPC) resource
By the end of this session, you should be able to effectively use remote HPC resources for running an emergency evacuation simulation and be able to understand how you this capability can work for your own code.
Contents¶
(Hyperlinks work only within the Jupuyter environment)
- Introduction
- Import Libraries and Setup Simulation
- Evacuation Simulation Overview
- How the Evacuation Simulation Works
- Running an Evacuation Simulation
- Driving Strategies used in the Evacuation Simulation
- Working With and Customizing Simulation Input Data
- Scaling Up with CyberGIS-Compute
- Next Steps: Creating your own Custom Job
Introduction¶
The evacuation simulation code base is flexible and can serve a variety of purposes. Broadly, the code models the process of evacuation on a road network in which roads are progressively closed by wildfire spread. Individual households, represented by a vehicle, must navigate out of the danger zone and re-route if the road they are currently on becomes blocked by the wildfire.
You will need to install legacy software versions (for backwards compatibility). Uncomment the first two lines to install older versions of networkx and osmnx.
Expected output:
Shapely version is 1.8.5.post1
Networkx version is 2.5.1
OSMnx version is 1.0.1# install key libraries
!pip install --upgrade networkx==2.5.1 --quiet
!pip install --upgrade osmnx==1.0.1 --quiet
#!pip install --upgrade shapely==1.8.5.post1 --quiet
import shapely
print("Shapely version is", shapely.__version__)
import networkx
print("Networkx version is", networkx.__version__)
import osmnx
print("OSMnx version is", osmnx.__version__)
In the next several cells, additional libraries and modules used in this notebook are imported and a few helper variables and functions are defined.
# import libraries
import glob
import IPython
from datetime import datetime
from shapely.ops import unary_union
import pytz
from pathlib import Path
import os
# set notebook parameters
out_path = Path(os.getcwd())
time_zone = pytz.timezone('America/Chicago')
# import functions and text of FireABM_opt.py
from FireABM_opt import *
fabm_file=open('FireABM_opt.py')
fabm_lines=fabm_file.readlines()
run_fabm_file=open('run_fireabm.py')
run_fabm_lines=run_fabm_file.readlines()
# define helper function for displaying code
# start and stop are 0-indexed, line numbers are 1-indexed
def display_code_txt(start, stop, lines_obj):
return IPython.display.Code(data="".join([(str(i+start+1)+" "+x)
for i, x in enumerate(lines_obj[start:stop])]), language='py3')
The code models the process of evacuation on a road network in which roads are progressively closed by wildfire spread.
There are two input datasets needed:
- Household distribution information
- A set of wildfire perimeters with timestamps
The code has two stages: init and run.
- In the init stage, a boundary for the evacuation zone is set. The initial positions of evacuee vehicles will be generated within the boundary according to the density of households. The position of the wildfire at timestamp 0 will be used to close intersecting road segments and no vehicles will be positioned on closed roads.
- In the run stage, the wildfire position is updated at set intervals and newly intersected roads are closed. Vehicles attempt to exit
First, we will run a small sample simulation to showcase working code. Before running the code, we create an output directory to save generated results.
# determine current path and make output directory for quick start
import os
out_path = os.getcwd() # save current path
if not os.path.isdir('demo_quick_start'): # create quick start output directory
os.mkdir('demo_quick_start')
The following line of code runs the wildfire agent-based model evacuation simulation one time and saves the results in the demo_quick_start folder.
Important parameters (these will be described in more depth later on):
-nv: number of vehicles to include in the simulation-sd: seed, this number is used to set the randomization of the initial vehicle positions-epath: current path-ofd: name of the output directory used to store results-strat: driving strategy used (quickest,dist, ordist+road_type_weight)-rg: formatted Osmnx road graph stored as a pickle file-exdsc: experiment description (a tag to help keep track of runs)
# run a small simulation
!python run_fireabm.py -nv 10 -sd 1 -epath "$out_path" \
-ofd demo_quick_start -strat dist -rg Sta_Rosa_2000.pkl \
-exdsc 'demo_run' -strd 1.0
If you have run the previous cell with the default parameters, you will find three types of results are saved in subfolders for each run:
- in folder
1files: A file of run information, which stores things like the number of vehicles, seeds, driving strategies, clearance times etc. - in folder
1trajs: A file of trajectories taken by each vehicle - in folder
1videos: A video of the completed simulation run
Note that the '1' at the start of the folder names is from the experiment number, a flag to help keep track of different groups simulation runs. It is set by default in run_fireabm.py.
In this section, we'll look at how the evacuation simulation code works in more detail.
Running the simulation model takes two steps. The simulation object needs to be called twice, once to set up the simulation by calling the __init__ function, and once to actually run the simulation using the run function.
Here the simulation __init__ function in FireABM_opt.py is shown. Relavent parameters are defined below.
# show the simulation init section
display_code_txt(1164, 1165, fabm_lines)
NetABM __init__ input parameter description:
g- road graph: the input Osmnx road graphn- number of vehicles: the total number of vehicles used in the simulation runbbox- bounding box: the bounding box of the evacuation zone, lbbox is created by the create_bboxes function with the following buffer [2.1, 4.5, 3, 3]fire_perim- fire perimeter: shapefile of fire perimetersfire_ignit_time- fire ignition time: 'SimTime' value for the first perimeter used in the simulation, can be adjusted to start with a later perimeter, 60 is used because is the first output fire perimeterfire_des_ts_sec- fire update time intervals to seconds: translates intervals between fire times to seconds, used to speed up or slow down a fire spread from the input shapefile, for these experiments 100 is used, so that the fire expands every 100 timesteps (seconds)reset_interval- reset fire interval: flag used to indicate the fire time has been translatedplacement_prob- vehicle placement probability: value name containing the placement probabilities per initial vehicle placementsinit_strategies- initial vehicle strategies: dictionary indicating which driving strategies are used and the percentage of vehicles that should be assigned to each strategy
Here the simulation run function in FireABM_opt.py is shown. Relevant parameters are defined below.
# show the simulation run section
display_code_txt(1442, 1443, fabm_lines)
NetABM run input parameter description:
mutate_rate- the road segment closure rate: ignored if a fire shapefile is given, if no fire shapefile it is the rate at which road segments will randomly become blocked at an update intervalupdate interval- the road closure interval: used for to determine how often the mutate rate will check to close roadssave_args- save file arguments: used to create simulation animation, containsfig,axcreated by thesetup_simfunction, the result file name, the video file name, the folder name for storing the results, i and j which can be used to keep track of iterating through seeds and driving strategies, the seed used, the short tag describing the treatment, the short text describing the experiment, the experiment number and notebook number, and which road graph file is used. More detailed on these can be found in the 'Simulation output structure and explanation' help documentcongest_time- congestion time: interval at which congestion is recorded
Note that nsteps, opt_interval, strategies, opt_reps, and mix_strat are not used for the current set of experiments.
In this section, we will run an example simulation on the full road graph.
run_fireabm.py calls both the __init__ and run functions as seen below.
# show the simulation __init__ section of run_fireabm.py
display_code_txt(164, 167, run_fabm_lines)
# show the simulation run section of run_fireabm.py
display_code_txt(168, 171, run_fabm_lines)
Note! Running the code in the following 2 cells will take approximately 15-20 minutes to complete
The following code demonstrates running a larger simulation using the full road graph used for manuscript experiments (Sta_Rosa_8000.pkl). Only 200 vehicles are used so that the runtime is ~20 minutes instead of multiple hours. However, since this takes a while, switch run_long_full_sim to True in order to run the simulation.
# the example full simulation takes ~15-20 minutes
# change this variable to True to run
run_long_full_sim = False
# run full example (shortest distance driving strategy, 200 vehicles)
if run_long_full_sim:
if not os.path.isdir('demo_full_example'): # create full example output directory
os.mkdir('demo_full_example')
if os.path.isdir(os.path.join("demo_full_example", "1files")):
print("You have likely already ran this cell: the results will be the same!")
else:
!python run_fireabm.py -nv 200 -sd 2 -epath "$out_path" -ofd demo_full_example -strat dist \
-rg Sta_Rosa_8000.pkl -exdsc 'Demo quickest strat comp to mjrds and dist' -strd 1.0 -rfn 'demo_result' \
-vfn 'demo_output'
else:
print("Change 'run_long_full_sim' to True to run this simulation!")
Once this has finished running, you can view the output data in the demo_full_example folder.
In this evacuation simulation, there are three driving strategies evacuees can choose frum. In this section the strategies will be explained in more detail and demonstrated on a small road graph.
Quickest path:
this driving strategy is commonly used in evacuation models
How to select the path:
- Select the shortest path from the vehicle position to the nearest exit using Dijkstra's algorithm weighted by both road segment length and road segment speed limit
- As the simulation progresses, at each time step, for each road segment that has at least one vehicle on it, estimate the current road segment speed by the average speed of all of the vehicles currently on the road segment
- each time at least one road segment's estimated speed is different from its usual speed (more than a small difference value to adjust for rounding), each vehicle will redetermine the path using the estimated speed in stead of the actual speed for each road segment containing vehicles
- there typically needs to be a relatively large amount of congestion for it to make sense to take a detour that is longer distance wise
- A new path, using the same method as described above, will also selected if a road segment on the current path is closed due to the wildfire spread
Shortest path:
this driving strategy is also commonly used in evacuation models
How to select the path:
- Select the shortest path from the vehicle position to the nearest exit using Dijkstra's algorithm weighted by road segment length
- A new path will only be selected if a road segment on the current path is closed due to the wildfire spread
Major roads:
this driving strategy is used in an attempt to more realistically model traffic behavior observed in evacuations
How to determine the path:
- Select the shortest path from the vehicle position to the nearest exit using Dijkstra's algorithm weighted by road type weight multiplied by road segment length. Road type weights are determined according to the table below. Road type is a value found in OpenStreetMap's 'highway' column.
- A new path will only be selected if a road segment on the current path is closed due to the wildfire spread
| OSM Road Type | weight |
|---|---|
| motorway, motorway_link, trunk, trunk_link | 1 |
| primary, primary_link | 5 |
| secondary, secondary_link | 10 |
| tertiary, tertiary_link | 15 |
| unclassified, residential, (other value) | 20 |
First we need to import the road graph. This particular graph only has two exits, both at the bottom left corner, in order to help visualize differences between paths chosen according to each driving strategy.
# import demo road graph used for driving strategy demo
road_graph_pkl = 'demo_road_graph.pkl'
road_graph = load_road_graph(road_graph_pkl)
gdf_nodes, gdf_edges = get_node_edge_gdf(road_graph)
(bbox, lbbox, poly, x, y) = create_bboxes(gdf_nodes, 0.1, buff_adj=[-1, -1, 0.5, -1])
The next cell displays the road graph and the bounding box.
# display road graph
check_graphs(gdf_edges, x, y);

As described above, road segment speeds and road types are important for the different routing strategies, so in the next two cells we view speeds and the road types found in this small road graph. Each segment has the same speed limit, which makes it easier to see differences between driving strategies.
# view speeds
view_edge_attrib(road_graph, 'speed', show_val=True, val=[1, 5, 10, 15, 20]);

Only one street has the designation of "motorway".
# view road types
view_edge_attrib(road_graph, 'highway')

Now we will run each driving strategy on this small graph with the following code blocks.
# make sure output directory exists
if not os.path.isdir('demo_driving_compare'):
os.mkdir('demo_driving_compare')
# set run parameters
seed = 2
j = 0
exp_no, nb_no = 0, 0
strats = ['quickest', 'dist', 'dist+road_type_weight']
treat_desc = ['100% quickest', '100% shortest distance', '100% major roads']
exp_desc = 'demo compare driving strats'
out_path = Path(os.getcwd())
vid_path = out_path / "demo_driving_compare" / "0videos"
# run simulations
if os.path.isdir(os.path.join("demo_driving_compare", "0files")):
print("You have likely already ran this cell: the results will be the same!")
else:
for i in range(len(strats)):
print('Starting simulation run for', strats[i])
start_full_run_time = datetime.now(time_zone)
road_graph_pkl = 'demo_road_graph.pkl'
road_graph = load_road_graph(road_graph_pkl)
gdf_nodes, gdf_edges = get_node_edge_gdf(road_graph)
(bbox, lbbox, poly, x, y) = create_bboxes(gdf_nodes, 0.1, buff_adj=[-1, -1, 0.5, -1])
fig, ax = setup_sim(road_graph, seed)
simulation = NetABM(road_graph, 200, bbox=lbbox, fire_perim=None, fire_ignit_time=None,
fire_des_ts_sec=100, reset_interval=False, placement_prob=None,
init_strategies={strats[i]:1.0})
simulation.run(save_args=(fig, ax, 'demo_driving_out', 'demo_driving_vid', 'demo_driving_compare',
i, j, seed, treat_desc[i], exp_desc, exp_no, nb_no, 'demo_road_graph.pkl'),
mutate_rate=0.000, update_interval=100)
end_full_run_time = datetime.now(time_zone)
print('Run complete run at', end_full_run_time.strftime("%H:%M:%S")+',', 'elapsed time:',
(end_full_run_time-start_full_run_time))
Now download and view the result videos in the demo_driving_compare folder. We'll start with the simplest driving strategy, shortest distance. Notice that all the vehicles on and to the right of the motorway road use the right most exit.
Now view the quickest driving strategy. Watch closely the vehicles that start at the center top, in this case many of them switch to use the left most exit because of the build up of congestion on the right one.
Finally, view is the major roads simulation. Here very few vehicles take the left most exit because the highway is preferred.
In order to run the full evacuation simulation in a different location, you will need to create a new road graph, use a new households file, and import a new wildfire perimeter shapefile. More details about these data and the actions needed to create them for a given study area are discussed below.
A road graph created with the OSMnx Python library is a form of a Networkx graph. This graph data structure contains nodes, edges, and data associated with nodes and edges.
The road graph is specifically a MultiDiGraph, which is a directed graph (i.e. an edge connecting node A and node B is considered different from an edge connecting node B to node A) that can contain self loops (a node can be connected to itself) and parallel edges (there can be multiple edges in the same direction between two nodes.
# view road_graph type (MultiDiGraph)
type(road_graph)
Networkx graph methods can be directly used to interact with the road graph and its data. For example, you can list nodes, and edges, and list data for each.
# list first nodes in graph
list(road_graph.nodes)[:5]
# list first edges in graph
list(road_graph.edges)[:5]
# list nodes and data
list(road_graph.nodes(data=True))[:2]
# list edges and data
list(road_graph.edges(data=True))[:2]
While the direct access to the Networkx structure is powerful, working with a road graph as a Geographic Data Files (.gdf) file format is a useful way to inspect data attributes for nodes and edges. The default view here can be easier to sort and filter data.
Here it is easy to inspect road graph node attributes. Each node has an OSM ID, x and y coordinates, a highway designation value, longitude and latitude coordinates, and a point geometry column.
# inspect the first values of the nodes file
gdf_nodes.head()
Edges connect nodes. Each edge has a starting and ending node, which are designated as u and v nodes. Key values are used to differentiate between two edges that connect the same two nodes in the same direction (i.e. parallel edges). Edges also have an id and an OSMid. They can have a street name, have a road type (highway), have an indication of direction, length, maxspeed, number of lanes, and geometry. Additional columns are created during preprocessing to use in the simulation.
# inspect the first values of the edges file
gdf_edges.head()
Refer to the FlamMap Documentation for creating simulated wildfires. For this manuscript, the fire tutorial was used to generate a series of output perimeters. These were resized and relocated to fit in the study area. Although the resulting fire spread is not realistic for the location, it demonstrates how the simulation code can use results generated in FlamMap.
Looking at the shapefile columns for the wildfire shapefile, we can see that FlamMap has generated attributes for the fire. The most important two columns used in the simulation are the geometry column, which contains a polygon that maikes up part of the fire perimeter at a specific point, and the SimTime colum, which contains the simulated time in minutes that each row belongs to.
# inspect fire
fire_file = load_shpfile(road_graph, ("fire_input",'santa_rosa_fire.shp'))
fire_file.head()
The following code shows the fire perimeters used in the simulation colored by 'SimTime', i.e. the number of minutes elapsed since the start of the simulation. Two different color portions can be seen because in this case the fire does not spread during the night.
# display fire
fire_file.plot(column='SimTime', legend=True)

Household data is used to initially place vehicles in proportion to households within census tracts. Households data have been gathered from US Census Data Table S1101 2014-2018 American Community Survey 5-Year Estimates, Table S1101. You can download a CSV from the Census Bureau with household data and join to census tract shapefiles that have been also downloaded from the Census Bureau. Althouugh this simulation code expects census tracts, it could be modified to use other geographic areas.
This shapefile contains basic information about the census tract from the Census Bureau and the number of households per census tract has been joined to the shapefile. Important columns here are Tot_Est_HH, which contains the ACS estimate of total households per census tract from the above table, and geometry with the census tract geometry.
# inspect households
hh_tract = load_shpfile(road_graph, ("households", "Santa_Rosa_tracts_hh.shp"))
hh_tract.head()
The following cell shows the estimated number of households per census tract in the Santa Rosa area.
# display households
hh_tract.plot(column="Tot_Est_HH", legend=True)

As one full simulation run using the quickest driving strategy can take approximately 5 hours to run, using remote HPC resources can be very useful to obtain simulation results. CyberGIS-Compute is service for running High Performance Computing (HPC) jobs from a Jupyter Notebook within the I-GUIDE platform. In this example, the FireABM simulation script is run twice, each separately using two different tasks.
This small example demonstrates how to run a serial script with no in-built parallelization multiple times on CyberGIS-Compute, how to pass parameters from a notebook to CyberGIS-Compute, how to access standard HPC variables (such as node_ids) from within a CyberGIS-Compute job, and how to specify the correct working and results directories for running the job script and downloading the results. The goal of this example is to demonstrate how to use CyberGIS-Compute with no or very little adjustments to the original serial code. The CyberGIS-Compute job in this section uses this repository: https://github.com/cybergis/cybergis-compute-fireabm.git .
The CyberGIS-Compute client is the middleware that makes it possible to access High Performance Computing (HPC) resources from within a CyberGISX Jupyter Notebook. The first cell loads the client.
# load cybergis-compute client
from cybergis_compute_client import CyberGISCompute
Next it is necessary to create an object for the compute client.
# create cybergis-compute object
cybergis = CyberGISCompute(url="cgjobsup.cigi.illinois.edu",
isJupyter=True, protocol="HTTPS", port=443, suffix="v2")
CyberGIS-Compute works by pulling data and information about the job from trusted github repositories. Each job requires a GitHub repository to be created and specified when the job is created. After the GitHub repository is created, the CyberGISX team must be contacted to review the repository and if approved, add it to the available repositories that can be used with CyberGIS-Compute. You can see which repositories are supported using the list_git function. The repository we will be using is linked under fireabm.
# list available repositories for jobs
cybergis.list_git()
The custom repository used in this example is https://github.com/cybergis/cybergis-compute-fireabm.git .
This repo contains the following key files:
- manifest.json: a file that controls how the CyberGIS-Compute is run
- runjobs.sh: a shell script that creates needed directories and runs run_fireabm.py
- run_fireabm.py: the top level python script that runs the simulation
- other files and directories: contain data and functions needed to run the simulation
manifest.json (https://github.com/cybergis/cybergis-compute-fireabm/blob/main/manifest.json) is a mandatory file. It must be a JSON file named manifest.json and must contain a JSON array of key value pairs that are used by CyberGIS-Compute. In particutlar, the "name" value must be set, the "container" must be set ("cybergisx-0.4" contains the same modules as a CyberGISX notebook at the time this tutorial notebook was created), and the "execution_stage" must be set. In this case "bash ./runjobs.sh" tells CyberGIS-Compute to run the shell script runjobs.sh when the job runs.
runjobs.sh (https://github.com/cybergis/cybergis-compute-fireabm/blob/main/runjobs.sh) is a shell script that runs when a CyberGIS-Compute Job is run. This script does the following actions:
- sets a
$SEEDvariable value based on the$param_start_value(a value set when the job is constructed within this Notebook) and#SLURM_PROCID(the task ID, a built in variable populated when the job runs on HPC) - creates a directory in the
$result_folder(a path set by the CyberGIS-Compute Client when the job is created) - on one task only: copies files to the
$result_folder - runs the python script run_fireabm.py (the serial starting script) passing in the
$SEEDvalue and the$result_folder value - on one task only: after the script is run, removes data files from the
$result_folder(note that for real examples, this task is better done in thepost_processing_stage
Variables: This shell script uses variables and directories set in a few different places. The $SEED variable is created in runjobs.sh. The $param_start_value is a value that is passed to the CyberGIS-Compute client from a notebook. This value is set in the param array within the .set() function in the next section of this notebook. #SLURM_PROCID is a built-in variable set on the HPC (other available variables can be found here: https://slurm.schedmd.com/srun.html#lbAJ)
Directories: CyberGIS-Compute client uses two primary directories which are set when the job is created. The paths to these directories can be accessed by environment variables. Although scripts are run in the $executable_folder, results should be written to the $results_folder. These folders are not in the same location. You might need to adjust your primary script if it by default writes result files in the same folder as the script. In this example, the $results_folder variable is passed to the python script, which requires an output path to use to write results.
Execution Stages: The CyberGIS-Compute client supports three stages: "pre_processing_stage", "execution_stage", and "post_processing_stage". These are each keys in the manifest.json file which expect a command to run as a value. An example of a manifest.json file that uses all three stages can be found here: https://github.com/cybergis/cybergis-compute-hello-world/blob/main/manifest.json . Ideally the clean up tasks should be performed in the "post_processing_stage" to ensure that all tasks in the execution stage are finished before performing clean up activities.
Other files and directories in the repo: The FireABM simulation needs some small input data files and a specific input directory structure. These files and directories are included in the GitHub repo and will be copied to the $executable_folder by the CyberGIS-Compute Client.
Using the show_ui() function, you can see the user interface for CyberGIS-Compute, which will open an interactive component like in the below image.

First, you will need to select a template. The template loads information from the git repository we mentioned above and uses it to populate settings for the job. The template selector can be seen in the image below.

Now you will need to select job specific parameters for the job, such as which HPC resource to run on, how it will run on the HPC resource, and any input values needed by the code. These parameters differ for each job template. You can select a tab to expand information for the parmeters within, and then adjust certain parameters. For this demo, use the already selected parameters.

Optionally you can give the job a custom name and provide an email address to get job status updates. Now the job can be submitted using the submit button at the bottom of the component.

Once the job has been submitted, you can view live updates through the logs.
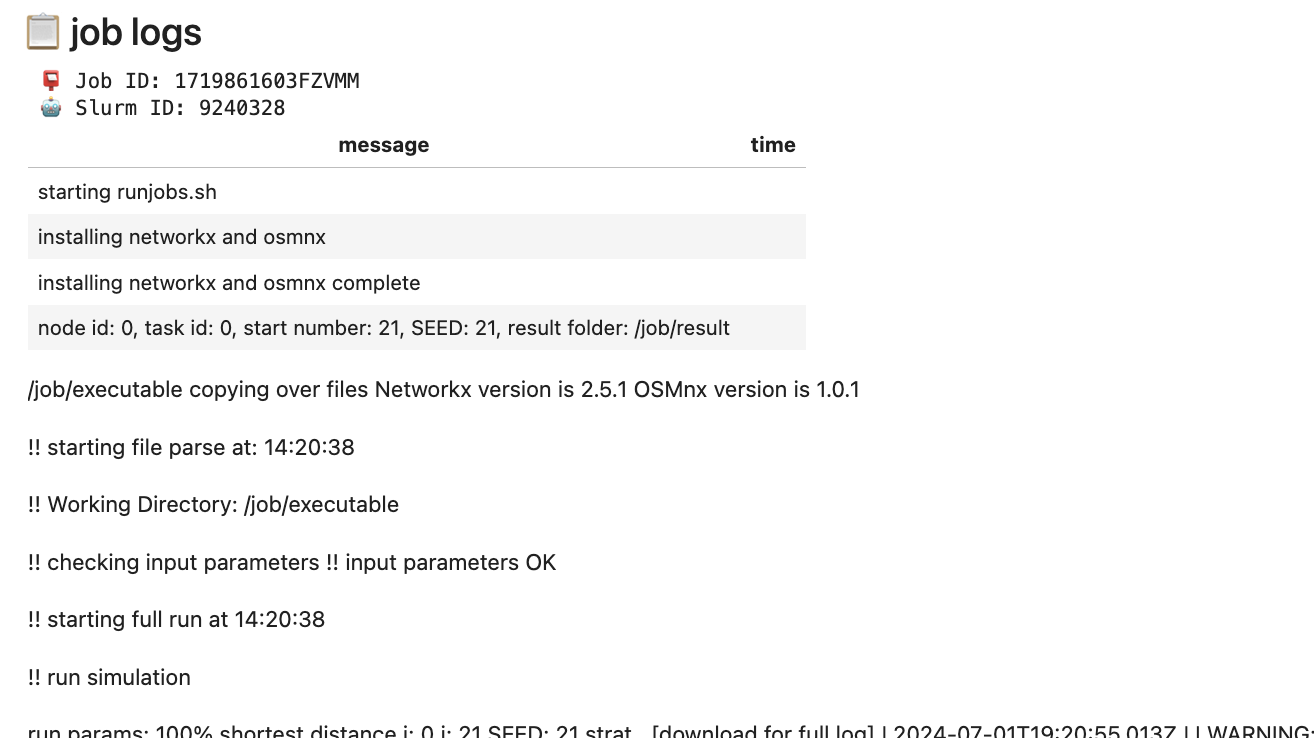
You can also check out the status on the Your Job Status tab, illustrated in the image below.
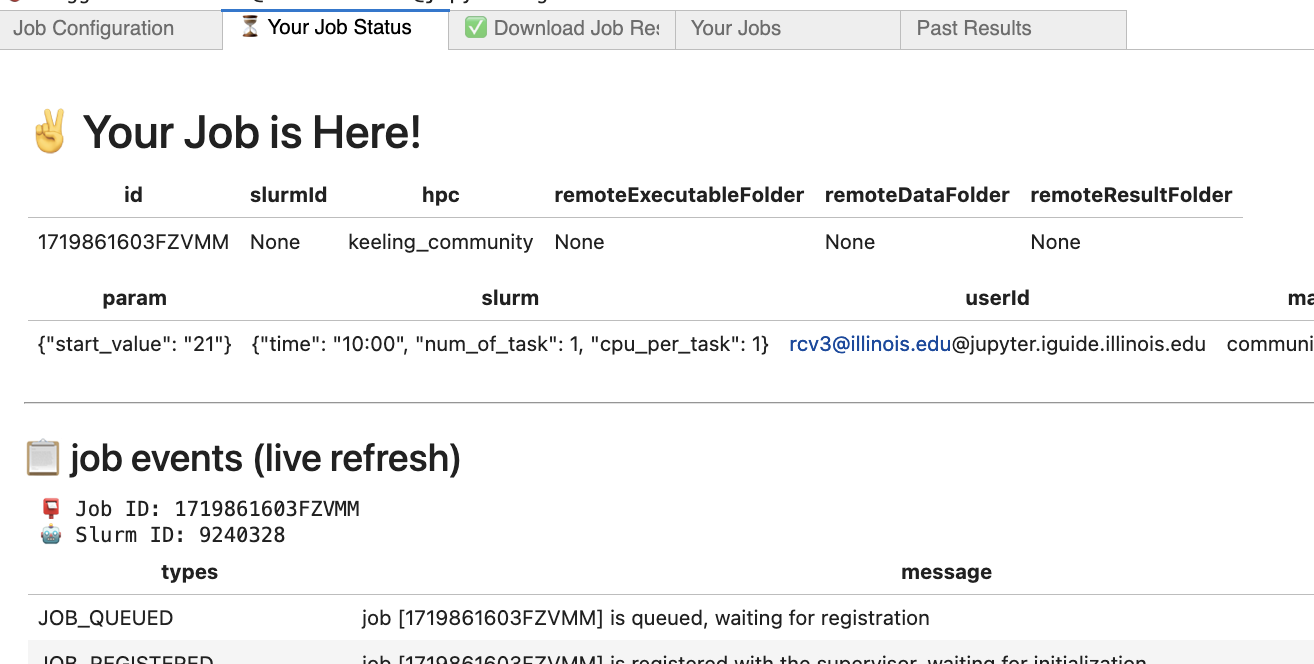
Once the job is complete, you will see a notification that it has finished.

Finally, you can go to the Download Job Results tab to download output generated by running the job and any output created by the job. It will download to a folder in your root Jupyter directory. For this example, select the folder demo_quick_start21 (the number might be different if you changed the start_value parameter). It will download to a globus_download_{JOBID} folder on your Jupyter enviornment, where JOBID is the ID of your cyberGIS-Compute job.
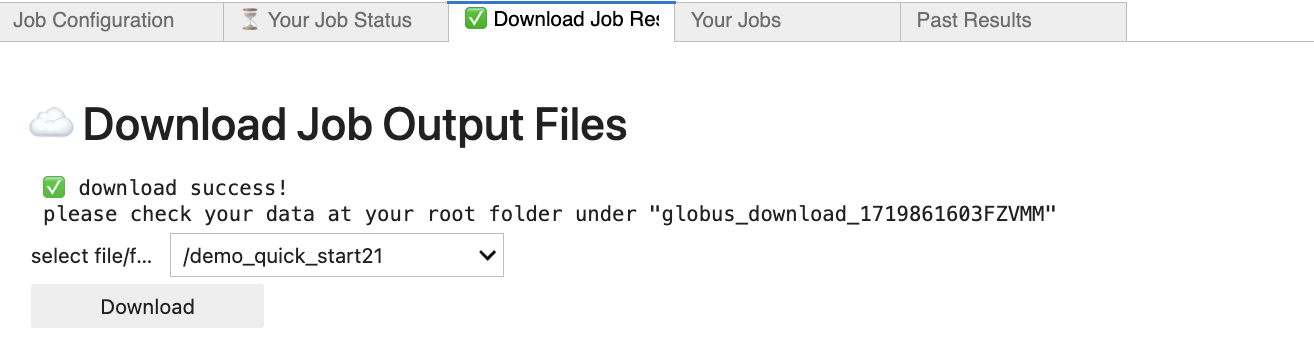
Using the above instructions in the How to Setup and Run the CyberGIS-Compute Job section, run this next cell to bring up the CyberGIS-Compute user interface. Set the parameters for the job and run the job. When the job has finished, download the results.
cybergis.show_ui()
If you are interested is using CyberGIS-Compute, documentation can be found at https://cybergis.github.io/cybergis-compute-python-sdk/index.html.
You can also learn more about setting up your own code to run on CyberGIS-Compute. This will involve setting up a GitHub repo with your code and a manifest.json file to direct how the code will run on a Slurm system.