Programming with CyberGIS-Jupyter¶
- Cell
- Add a cell: single click on a cell --> Menu --> Insert
- Delete a cell: single click on the cell to delete --> Menu --> Edit --> Delete Cells
- Reorder a cell: click on a cell --> up arrow or down arrow
- Change cell type: single click on a cell ---> Menu --> Cell Type
- Edit cell
- Markdown: double click (basic syntax reference)
- Code: single click
- Run a cell: single click on a cell --> Run (or Shift + Enter)
- Run all cells: Menu --> Cell --> Run All
- Clear all cell output: Menu --> Cell --> All Output --> Clear
- Kernel
- Change kernel: Menu --> Kernel --> Change kernel
- Choose versioned kernel (eg XXXXX-0.8.0) before sharing
- Restart kernel: Menu --> Kernel --> Restart (& Clear output)
- Change kernel: Menu --> Kernel --> Change kernel
- See all notebooks (Tree View) on CyberGIS-Jupyter
- On CyberGIS-Hub page: click on "Launch CyberGISX" at the upper-right corner
- On an opened notebook page: remove notebook filename (XXXX.ipynb) from browser address bar
- Troubleshooting
- Restart kernel
- Restart CyberGIS-Jupyter (save notebook first!): Control Panel --> Stop My Server --> Start Server
- Bug Report button
- Announcement area (maintenance plan, release notes)
- More Info
- Try it out now
Task 1: Add one new code cell after this cell¶
Hint: Single click on this cell --> go to Menu --> Insert --> Insert Cell Below
Task 2: Change the new cell's type to Markdown, and write something in it
Hint: Single click on the new cell --> go to Menu --> Cell --> Cell Type --> Markdown; Single click on the new cell ---> write some Markdowns see basic syntax reference; Click on the "Run" button on the tool bar;
Task 3: Uncomment the Python codes in the cell below and run it¶
Hint: Single click on the cell below --> Remove the Pound sign ('#') --> press Shift + Enter keys together (or click on the 'Run" button on the tool bar)
#print("hello world")
Task 4: clean all output of this notebook¶
Hint: go to Menu --> Cell --> All Output --> Clear
------------- Below is the main section of the Mapping and Visualization notebok -----------------¶
Introduction¶
This notebook will walk you through some basic techniques of conducting Interative Mapping and Data Visualization in the CyberGIS-Jupyter environment. We will retrieve the latest COVID-19 data from the Illinois Department of Public Health (IDPH) website, examine and preprocess the data, make plots of daily new cases by counties using matplotlib, create an interactive map with ipyleaflet to visualize weekly channge of new cases across the state, and finally link map and plot together.
After finishing this notebook, you will have a "app-style" notebook like the screenshot below. You are encouraged to tweak the codes a little bit to visualize other COVID-19 indices, such as deaths and testings.

Setup¶
This cell is to import required modules and libs. A breif description on the purpose of each libs can be found below:
- json - standard Python module for JSON format I/O operations
- wget - for downloading files from URLs
- numpy - for handling N-dimentional arrays and numerical computing
- pandas - for tabular data analysis and manipulation
- ipyleaflet - for interactive mapping in Jupyter Notebook environment
- branca - for dealing with colormaps
- matplotlib - for creating plots and figures
import json
import wget
import numpy as np
import pandas as pd
import geopandas as gpd
import ipyleaflet
from branca import colormap
import matplotlib.pyplot as plt
# for interactive charting
%matplotlib notebook
Data retrieval and preprocessing¶
The Illinois Department of Public Health has a COVID-19 data portal that provides different metrics and data, including "county-level histrorical cases, deaths and tested", "hospitalization data", "vaccine administration data", "zipcode-level cases and tested data" and others. As noted on the website, data avaialbility, update frequency, data format and metrics reported are subject to change.
Since IDPH may choose to stop updating the data from their website or change the format in the future, we downloaded the data as of Nov 16, 2021 and saved it (filename: idph_counties_Nov16_2021.csv) alongside the notebook for archive. You can also programmatically download the latest "county-level histrorical cases, deaths and tested" data on the fly by uncommenting some codes in the cell below.
Download data from IDPH website¶
# By default, use data downloaded from IDPH as of Nov 16, 2021
idph_counties_csv = "./data/idph_counties_Nov16_2021.csv"
## Uncomment the 2 lines below to download latest data from IDPH on the fly
## IDPH may have removed or changed the data format after this notebook was developed
## So in that case you would need to change codes accordingly
## see: https://dph.illinois.gov/covid19/data/data-portal/all-county-historical-snapshot.html
idph_counties_url = "https://idph.illinois.gov/DPHPublicInformation/api/COVIDExport/GetSnapshotHistorical?format=csv"
idph_counties_csv = wget.download(idph_counties_url, out="./idph_counties.csv")
print("Using data at {}".format(idph_counties_csv))
Examine raw data¶
The raw data is a csv file. We load it into a pandas dataframe (the 1st row is ignored as it is the title line).
df = pd.read_csv(idph_counties_csv, skiprows=1, parse_dates=['ReportDate'])
df
Each row includes metrics of a specific county reported on a specific day. We can see the earliest data is from 2020-03-17 and the rows at the bottom are the most recent data.
List all county names. Note that IDPH separates Chicago city area from from Cook county in this dataset, and it treats Chicago as standalone county.
df.CountyName.unique()
Plot time series data for a county¶
We will plot the time series of daily new cases (metric/column name: "CasesChange") for a specific county you selected. You may change the county name or the metric/column name and re-run the following cells to visualiae a different plot of interest.
county_name = "Chicago" # pick a county from above and put it here
metric_name = "CasesChange" # which metric/column to plot, see the headers of the original dataframe
Here we extract data for the county selected.
one_county = df[df["CountyName"]==county_name].set_index("ReportDate")
one_county
Plot the selected metric/column ("CasesChange" by default). The plot is created with matplotlib. Pandas has build-in support for matplotlib so we can make a plot from a panda dataframe directly.
fig1, ax1 = plt.subplots(1,1, figsize=(8,4))
title = 'COVID-19 {} - {}'.format(metric_name, county_name)
one_county[metric_name].plot(ax=ax1, title=title)

Visualize weekly change of new cases at county level across the state¶
In this section, we will create a Choropleth Map to visualize the weekly change of new cases at county level across all counties in the state. We will randomly pick a date (day0) as the starting point, and look back for 1 week and calculate the number of new cases reported for that week (cases_current_week). We then look back for another week and caculate the same metric (cases_last_week). The weekly change rate is (cases_current_week - cases_last_week)/cases_last_week * 100%, and is calculated county by county. If the resulting number is postive (or negative), that means we are getting more (or less) cases than last week. The magnitude shows how fast the situation is changing, and we will use different colors to repreent them on the map.
There are 2 edge cases:
a) If there are new cases for current week (current_week is not 0) but no new cases reported for the last week (cases_last_week=0), the pandas calculaed change rate will become positive infinity (numpy.Inf) as the denominator is 0. This case is fine as we will handle it in data classification;
b) If current_week and last_week are both 0, the pandas calculation will give numpy.NAN (Not A Number). We would need to replace it with 0 before data classfication.
Note: This metric is selected for demo purpose only. Using a single metric alone may mislead you.
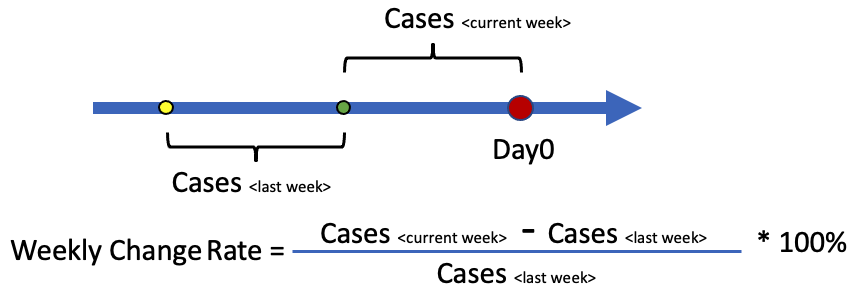
Calcuate weekly change rate¶
Here we pick a date as the day0 and extract "CumulativeCases" on that day for all counties. Be sure the date selected is within the range of the data and at least 2 weeks after the earilest reporting date (2020-03-27).
Here we calcuate number of new cases reported for current week (cases_current_week) and last week (cases_last_week).
day0 = np.datetime64('2021-11-16') # pick a date in the format of YYYY-MM-DD
# calculate new cases for this week
cum_cases_day0 = df[df["ReportDate"]==day0].set_index("CountyName").CumulativeCases
day_1week = day0 - np.timedelta64(1,'W')
cum_cases_1week = df[df["ReportDate"]==day_1week].set_index("CountyName").CumulativeCases
cases_current_week = cum_cases_day0.sub(cum_cases_1week)
# calculate new cases for last week
day_2week = day0 - np.timedelta64(2,'W')
cum_cases_2week = df[df["ReportDate"]==day_2week].set_index("CountyName").CumulativeCases
cases_last_week = cum_cases_1week.sub(cum_cases_2week)
pd.DataFrame({'Current Week': cases_current_week,'Last Week':cases_last_week}).sort_values(by="Last Week")
Calcuate weekly change rate for all counties, and sort them by the rates. We replace any numpy.NAN with 0 and leave any nump.Inf as is. You can check if any county has Postive Infinity (numpy.Inf).
weekly_change_rate = cases_current_week.sub(cases_last_week).div(cases_last_week).fillna(0)
weekly_change_rate.sort_values().to_frame("Change_Rate")
Data classification and Colormap¶
We have calculcated the weekly change rate for every county. To visualize them on the map, we need to classify this metric into several classes and assign each class a different color.
Here we classify the weekly change rate into 5 classes. Note that we are doing manual data classification and the breaks we chose are pretty arbitrary. How to do the data classifiation mainly depends on the data itself and how you want to represent them on the map. Sometimes trial and error might be needed to find the "best" classification. Also there are other more advanced methods and tools. See Data Classification For Choropleth Maps and [MapClassify].(https://github.com/pysal/mapclassify) for details.
> +50% Class 1
+10% to +50% Class 2
-10% to +10% Class 3
-10% to -50% Class 4
< -50% Class 5# the function that maps weekly change rate values to class 1-5
def classify(v):
if v > 0.5:
color_index = 1 # class 1 - change rate > 50%
elif v > 0.1:
color_index = 2 # class 2 - change rate 10% to 50%
elif v > -0.1:
color_index = 3 # class 3 - change rate -10% to +10%
elif v > -0.5:
color_index = 4 # class 4 - change rate -50% to +-10%
else: # < -0.5
color_index = 5 # class 5 - change rate < -50%
return color_index
Apply the above classify() function to every county in the "weekly chanage rate" dateframe. The resulting dataframe lists county names and assigned color indices.
weekly_change_rate_class = weekly_change_rate.apply(classify)
weekly_change_rate_class.to_frame("Class")
Once the data is classified, we can pick colors for every class. The library branca provides a large collection of prebuilt color ramps. Here we have picked a Red-Yellow-Green color ramp. You may uncomment the following cell to see more avaiable color ramps.
#colormap.linear
cm_linear = colormap.linear.RdYlGn_08
cm_linear
We create 5 discrete color steps and assign class indices to them:
N_color_steps = 5 # How many discrete color steps
# The "cm" object (color map) is callable that takes a index and returns color code.
cm = cm_linear.to_step(index=range(N_color_steps+1), round_method="int")
def display_colormap(cm_func, vlist):
from IPython.display import HTML
n = len(vlist)
s = '<svg height="40" width="{}">'.format(n*40) \
+ "".join(['<circle cx="{}" cy="20" r="20" fill="{}"/><text x="{}" y="25">{}</text>'.format(i*40+20, cm_func(vlist[i]), i*40+15, vlist[i]) for i in range(len(vlist))]) \
+'</svg>'
return HTML(s)
display_colormap(cm, range(1, N_color_steps+1))
Red Class 1 > +50%
Orange Class 2 +10% to +50%
Yellow Class 3 -10% to +10%
Light Green Class 4 -10% to -50%
Green Class 5 < -50%Create a choropleth map with ipyleaflet¶
Here we use ipyleaflet for mapping, which is a Jupyter extension that brings in leaflet features to notebook environment. (Note that there also are other tools avaiable you can use to creates maps in notebook, such as folium, plotly, carto, mapbox and arcgis.)
We first ceate a "map" object, center it at Illinois, and add some basic controls to the map including a scale bar and a layer control. For more map control opntions, see here.
# create a ipyleaflet map obj, centering at Illinois
map = ipyleaflet.Map(center=[40.6, -89.6], zoom = 6)
# add a layer control at the topright
map.add_control(ipyleaflet.LayersControl(position='topright'))
# add a scale bar at the bottomleft
map.add_control(ipyleaflet.ScaleControl(position='bottomleft'))
map
In the "data" folder, there is a GeoJSON file ("idph_geometry.geojson") that contains geomery (polygon) for all Illinois counties. A "Chicago county" was added to make it compatible with IDPH data. We can use GeoPandas to have quick inspection on it.
# geojson file has county geometry (polygon)
county_geomoetry_geojson = "data/idph_geometry.geojson"
gpd.read_file(county_geomoetry_geojson)[["id", "geometry"]]
We put everything together using the ipyleaflet.Choropleth class. There are 3 parameters we need to pay attention to: "geo_data" is the geometry (county polygon) to plot; "choro_data" is a dictionary that maps geometry (county) to class indices (classified weekly change rate); "colormap" is the colormap funtion that converts class indices into colors.
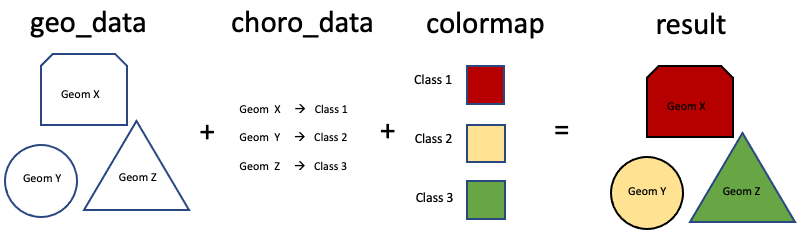
with open(county_geomoetry_geojson, 'r') as f:
layer = ipyleaflet.Choropleth(
name="Weekly Change of New COVID-19 Cases",
geo_data=json.load(f), # County geometry (geojson file)
choro_data=weekly_change_rate_class.to_dict(), # Geometry ID --> Class Index
colormap=cm, # Class Index --> Color
style={'fillOpacity': 0.8})
map.add_layer(layer)
map
Add a legend to the map
legend = ipyleaflet.LegendControl({"+50%": cm(1),
"+10% to +50%": cm(2),
"Steady (-10% to +10%)":cm(3),
"-10% to -50%":cm(4),
"-50%":cm(5)},
name="Weekly Change of New Cases",
position="bottomright")
map.add_control(legend)
App-style Interactive Map¶
The ipywidget allows you to monitor user actions on the map and make responses accordingly.
In this case, when a county is being clicked, we catch the county id (name) and plot the daily new cases time series as we did above, making it a app-style interactive map.
def layer_on_click(**kwargs):
global ax2
ax2.cla() # clear previous plot
county_name=kwargs["id"] # get the id (name) of the clicked county
one_county = df[df["CountyName"]==county_name].set_index("ReportDate") # extract data for this county
one_county.CasesChange.plot(ax=ax2, title='COVID-19 Daily Cases - {}'.format(county_name)) # plot time series
fig2, ax2 = plt.subplots(1,1, figsize=(9,4))
fig2.suptitle("(Click on the Map to view COVID-19 Daily Cases)")
layer.on_click(layer_on_click) # monitor mouse click event on the layer
map

Using this Metric Alone May Mislead You¶
This metric is selected for demo purpose only. Using this single metric alone may mislead you! For example, say a county's covid cases have been pretty bad and are on the top of the curve for a long time. However the weekly change rate could be a relative small value because numbers of new cases between thest weeks are close.