Particle Swarm Optimization for Calibration in Spatially Explicit Agent-Based Modeling¶
Authors: Alexander Michels, Jeon-Young Kang, Shaowen Wang
Special thanks to Zhiyu Li and Rebecca Vandewalle for suggestions and feedback on this notebook!
This notebook is related to an upcoming publication entitled "Particle Swarm Optimization for Calibration in Spatially Explicit Agent-Based Modeling." The abstract for the paper is:
A challenge in computational modeling of complex geospatial systems is the amount of time and resources required to tune a set of parameters that reproduces the observed patterns of phenomena of being modeled. Well-tuned parameters are necessary for models to reproduce real-world multi-scale space-time patterns, but calibration is often computationally-intensive and time-consuming. Particle Swarm Optimization (PSO) is a swarm intelligence optimization algorithm that has found wide use for complex optimization including non-convex and noisy problems. In this study, we propose to use PSO for calibrating parameters in spatially explicit agent-based models (ABMs). We use a spatially explicit ABM of influenza transmission based in Miami, Florida, USA as a case study. Further, we demonstrate that a standard implementation of PSO can be used out-of-the-box to successfully calibrate models and out-performs Monte Carlo in terms of optimization and efficiency.
Particle Swarm Optimization (PSO) was first introduced in 1995 by James Kennedy and Russell Eberhart. The algorithm began as a simulation of social flocking behaviors like those exhibited by flocks of birds and schools of fish, specifically of birds searching a cornfield, but was found to be useful for training feedforward multilayer pernceptron neural networks. Since then, PSO has been adapted in a variety of ways and applied to problems including wireless-sensor networks, classifying biological data, scheduling workflow applications in cloud computing environments, Image classification and power systems. In this notebook we explore PSO's usefulness for calibration, with a focus on spatially-explicit agent-based models (ABMs).
Table of Contents¶
- Why PSO?
- Particle Class
- The PSO Class
- Running It
- Adding Your Own Model
- Running It on the Command Line or HPC
- Spatially-Explicit ABMs
- Learn More
Note: You must run the cell below to import the required packages or the rest of the notebook will not work.
To run the notebook, please uncomment and run the cell below and then restart the kernel using Kernel -> Restart Kernel. You should then be able to run the notebook as normal.
# !pip install imageio
# import required packages
""" PSO class """
from PSO import *
""" Viz """
from IPython.display import Image, display, Markdown, Math
import ipywidgets
import matplotlib
import matplotlib.pyplot as plt
import networkx as nx
import pandas as pd
import shutil
import warnings
%matplotlib inline
#warnings.filterwarnings('ignore')
# use the following for dark theme:
plt.style.use('dark_background')
Why Particle Swarm Optimization (PSO)?¶
Model calibration is essentially an optimization problem: we want to find the parameters (which can be thought of as a location in a parameter space) which minimize or maximize some metric, often error (RMSE, MAE, etc.). A model with $n$ parameters can be thought of as an $n$-dimensional parameter space, which each choice of parameters represents a point in that space $\overrightarrow{x}=(x_{1},\cdots, x_{n})$. Of course we usually don't want to consider every point in $\mathbb{R}^{n}$, we usually have a set of bounds for our parameters, which we will call our feasible region $\mathcal{C}$.
So given a model $m$, we want to find the parameters $\overrightarrow{x}=(x_{1},\cdots,x_{n})$ such that $\overrightarrow{x}\in \mathcal{C}$ that minimizes the error of the model $err(m(\overrightarrow{x}))$. If we could calculate this $err(m(\overrightarrow{x}))$ for every point $\overrightarrow{x}\in\mathcal{C}$, we would get an error surface. Model calibration seeks to find the minimum point in this error surface. Of course, with continuous variables or computationally intensive models, it isn't possible or feasible to check every possibility, so we need to know how best to find the approximate answer without just checking every possible set of parameters (or point in the feasible reason $\mathcal{C}$).
This is relatively straight-forward some of the time, like when there is no randomness and when the error surface is convex, but in spatially-explicit agent-based modelling, those assumptions are often violated. Spatially-explicit agent-based models (SEABMs) usually incorporate some level of randomness and often have complex error surfaces which makes parameter calibration difficult. Non-convex optimization problems are known to be NP-hard and some have even been shown to be NP-hard to solve approximately! Thus to tackle this problem, we need an optimization method that works well on non-convex problems and performs well on noisey objective functions and PSO has been shown to meet both of these criteria!
In the rest of the notebook, we will learn more about the PSO method and apply it to some non-convex and noisey functions to put it to the test! The basic idea is this: we have a set of particles which move through the our parameter space. Their "fitness" is determined by the error of the model using their position in space as parameters. The particles communicate, using their "swarm intelligence" to try to determine the best set of parameters.
Particle Class¶
Below is the code for a simple Particle that will makeup our swarm. The Particle has a few important functions:
__init__- intializes the Particle object with a max velocity and bounds. The Particle picks a random point in the bounds as its initial position and generates a random velocity in $[-1,1]^N$ where $N$ is the dimension of the bounds.copy_from- copies position, velocity, and error information from another Particle object. Useful for syncing when using multi-processing.evaluate- evaluates the fitness of the Particle's position using the cost function if the Particle is in bounds.func_selis a dictionary that provides information to the cost function such as particle position (x) and other necessary parameters.update_velocity- uses its best position and its neighbors best position (pos_best_gwhich stands for position best global) to calculate a new velocity. This calculation uses a constriction factor and velocity clamping.
Velocity Determination¶
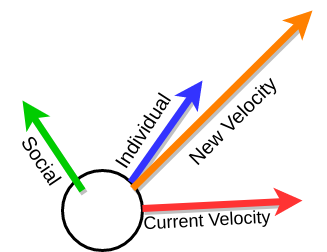
Particles use input from their environment and their neighbors to try to figure out which direction will result in better positions.
- Current Velocity is the direction that the particle is currently going in.
- Individual is the individual particle's best position in space.
- Social is the best position in space seen by the particle's neighbors, defined using a neighbor graph.
The original equation (Kenedy & Eberhart 1995) was:
$$\overrightarrow{v}_{t+1} = \overrightarrow{v}_{t}+2\cdot \beta_{1} (pbest-curr) + 2\cdot \beta_{2}(gbest-curr)$$where $\overrightarrow{v}_{i}$ is velocity at timestep $i$, $\beta_{1},\beta_{2}$ are uniform random variables [0,1], curr is the current position, pbest is the personal best position, and gbest is the global best position. The calculation means that a particle's velocity is a sum of its current velocity (momentum), cognitive/individual input, and social input. They note in their paper that "the stochastic factor was multiplied by 2 to give it a mean of 1 so that agents would "overfly" the target about half the time"
Our velocity determination is very similar, but uses a few suggested improvements. Much of our improvements come from a paper by Bratton & Kennedy (Defining a Standard for Particle Swarm Optimization). Two particularly helpful improvments described by Bratton & Kennedy are due to the work of Clerc (The swarm and the queen: towards a deterministic and adaptive particle swarm optimization) and Eberhart & Shi (Comparing inertia weights and constriction factors in particle swarm optimization) who suggested a "constriction factor" to help the algorithm converge and using maximum velocities to limit particles from shooting off away from the bounds. Using the work from these papers, the new velocity update formula is:
$$\overrightarrow{v}_{t+1}=\chi (\overrightarrow{v}_{t}+c_{1}\beta_{1}(pbest-curr)+c_{2}\beta_{2}(gbest-curr))$$$$\chi = \frac{2}{\|2-\phi-\sqrt{\phi^{2}-4\phi}\|}, \phi=c_{1},c_{2}$$$\chi$ above describes the constriction factor and as discussed in Bratton & Kennedy's paper, $\phi=4.1$ ensures convergence, thus giving us that $c_{1},c_{2}=2.05$ and $\chi\approx0.72984$. Note that here "gbest" refers to "the best position obtained by the particle's neighbors" which can be the global best if all particles are connected, but varies based on the topology of the particle communication structure (see below).
# data for plotting velocity
beta_1, beta_2 = random.random(), random.random()
curr = [0,0] # current location
v_t = [4, -6] # current velocity
pbest = [-7,2] # person best location
gbest = [9,8] # global best location (according to neighbors)
Below you can explore how simple velocity determination works. The colors match the figure above so:
- Red represents the current velocity
- Blue represents the individual influence
- Green represents the social influence
- Orange is the new velocity
# plot velocity determination
# basic (no constriction factor) velocity determination
origin = np.array([[curr[0]]*4,[curr[1]]*4]) # current location
individual = 2*beta_1*np.subtract(pbest, curr)
social = 2*beta_2*np.subtract(gbest, curr)
v_t1 = np.add(np.add(v_t, individual), social)
V = np.array([v_t, individual, social, v_t1])
plt.xlim([-10,10])
plt.ylim([-10,10])
plt.quiver(*origin, V[:,0], V[:,1], color=['r','b','g','orange'],scale=50)
plt.show()

Below you can see the effect of using the constriction factor.
# plot velocity determination
# using constriction factor
c1 = 2.05 # cognitive constant
c2 = 2.05 # social constant
phi = c1 + c2
k = 2.0 / abs(2 - phi - math.sqrt(phi ** 2 - 4 * phi))
display(Math(r'c_1 = {} \\c_2 = {},\\ \phi = {}\\ \chi = {}'.format(c1,c2,phi,k)))
origin = np.array([[curr[0]]*4,[curr[1]]*4]) # current location
individual = c1*beta_1*np.subtract(pbest, curr)
social = c2*beta_2*np.subtract(gbest, curr)
v_t1 = k*np.add(np.add(v_t, individual), social)
V = np.array([v_t, individual, social, v_t1])
plt.xlim([-10,10])
plt.ylim([-10,10])
plt.quiver(*origin, V[:,0], V[:,1], color=['r','b','g','orange'],scale=50)
plt.show()

The vectors above look the same, so what's the difference?
As mentioned above, the constriction factor comes from work by Eberhart & Shi which found that "the best approach to use with particle swarm optimization as a 'rule of thumb' is to utilize the constriction factor approach". It is meant to slightly scale down the new velocity. This is useful because it ensures that the particles will converge on a single solution.
The PSO Class¶
The class looks long and complicated, but rest assured, much of the code is dealing with PSO parameters and logging the results out. The functions are:
__init__- Initializes a swarm and calls the other necessary functions for PSO. It takes in a cost function (costFunc), bounds (bounds) and an argument dictionary which is used for PSO parameters such as whether or not to make a gif.set_neighbor_graph- sets a neighbor graph for the Particles. Neighbors communicate about most fit positions.optimize- the optimization loop. Until we reach a given number of generations/iterations, the optimize loopgenerate_gif- generate a gif of the run. This also means that the surface will be plotted at each step which is not feasible for computationally intensive functions like ABMs.plot_surface- plots the surface with the history of the particles. Again note that this is not feasible for computationally intensive functions.plot_surface_this_timestep- used ifgif==Trueto produce a snapshot of the surface with the particle position and movement at eash timestep. These snapshots are compiled into a gif at the end of the run
PSO Topology¶
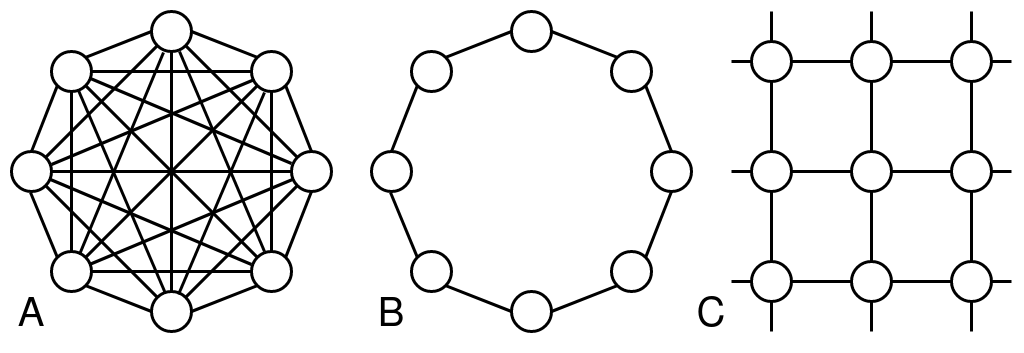
The topology or neighbor graph of the particle determines which particle communicate with each other. This creates the "social" component of the velocity determination function and allows the particles to cooperate when finding the best set of parameters.
The original Particle Swarm Optimization implementation relied on a "global best", but there has been extensive work to explore different communication network structures. The two most commonly explored graph structures are usually referred to as "gbest/global best" which describes a fully connected graph where each particle is connected to each other and "lbest/local best" which describes a graph where each particle is only connected to two others forming a ring. The are illustrated in the above figure on the left and right. In our implementation, they are called "fullyconnected" and "ring".
Work has also been done to explore other topologies like random graphs, "pyramid", "star", "small world", and von Neumann based on von Neumann neighborhoods. I highly recommend the papers by Kennedy & Mendes (Population Structure and Particle Swarm Performance) as well as Bratton & Kennedy's work (Defining a Standard for Particle Swarm Optimization) as a starting point. Kennedy & Mendes found that von Neumann worked most consistently while more recent work by Bratton & Kennedy recommends a ring topology.
We have implemented the "gbest" (fullyconnected), "lbest" (ring) and von Neumann (vonNeumann) topologies.
# function for creating graph describing communication between particles
def set_neighbor_graph(num_particles, topology): # add more topologies
neighbor_graph = np.zeros((num_particles, num_particles)) # turn into numpy structure
if topology == "fullyconnected":
for i in range(num_particles):
for j in range(num_particles):
neighbor_graph[i, j] = 1
elif topology == "ring":
for i in range(num_particles):
for j in range(num_particles):
if j == i - 1 or j == i + 1:
neighbor_graph[i, j] = 1
elif i == 0 and j == num_particles - 1:
neighbor_graph[i, j] = 1
elif i == num_particles - 1 and j == 0:
neighbor_graph[i, j] = 1
elif topology == "vonNeumann":
""" https://doi.org/10.1109/CEC.2002.1004493 """
n = num_particles
r = math.floor(math.sqrt(n))
for i in range(n):
neighbor_graph[i, (i + 1) % n] = 1
neighbor_graph[(i + 1) % n, i] = 1
neighbor_graph[i, (i - 1) % n] = 1
neighbor_graph[(i - 1) % n, i] = 1
neighbor_graph[i, (i + r) % n] = 1
neighbor_graph[(i + r) % n, i] = 1
return neighbor_graph
In the fully connected topology, all particles talk to each other so information about where the best location might be spreads fast. This fast spread of information means that particles often converge quickly on a singular place which can be good for exploring a small area in-depth, but can mean that the particles don't adequately explore the full space.
# fullyconnected topology
num_particles = 20
A = set_neighbor_graph(num_particles, "fullyconnected")
G = nx.from_numpy_array(A, create_using=nx.DiGraph)
nx.draw(G)

The ring topology has the particles connected in a large cycle or ring. This means that information moves very slowly through the network. Generally this means that the particles explore more of the space and take longer to converge on a single spot.
# ring topology
A = set_neighbor_graph(num_particles, "ring")
G = nx.from_numpy_array(A, create_using=nx.DiGraph)
nx.draw(G)

The von Neumann topology splits the difference between the "fullyconnected" and "ring" topologies. Particles are more connected than in the ring, but not quite as connected as in the fullyconnected one.
# vonNeumann topology
A = set_neighbor_graph(num_particles, "vonNeumann")
G = nx.from_numpy_array(A, create_using=nx.DiGraph)
nx.draw(G)

Running It¶
Before we run the algorithm, let's discuss the full set of parameters which are passed through a JSON file (or dictionary as we will see below). There is a test.json file that gives sample parameters:
!cat test.json
The parameters above mean:
functiongives information on the function to optimize.function/dim_descriptioncan be a list of labels for the different dimensions. For example with the SEIR model we used["introRate","reproduction","infRate"]. If nothing is supplied, we use x[0],...x[n].function/dimensiongives the number of dimensions in the parameter space (the number of parameters).function/functionspecifies the function name in text. This is used byPSO.py'smainfunction to determine the correct function to optimize.- you can also pass any other amount of information in this
functiondictionary in case your function/model needs other information! See Adding Your Own Model to learn more about adding your own model.
gifis a boolean that specifies whether or not you want to make a gif of the algorithm run. SET TO FALSE FOR COMPUTATIONALLY INTENSIVE FUNCTIONS OR MODEL because it uses 40,000 evaluations per iteration to plot the error surface.headlessis a boolean.Trueminimizes the amount printed to the terminal.max_velocityis used to specify the maximum velocity. See the velocity determination information above for more info.output_dirspecifies the path you'd like to store outputs in, this is joined to "./outputs". So for example if you specified "test", the outputs would be stored in "./outputs/test/". This is useful for grouping together runs of the algorithm.particlesgives the number of particles.seedis the seed for a random number generator. "None" uses no seed.terminationallows us to specify when the algorithm should terminate.termination/termination_criterionspecifies how the PSO algorithm knows when to stop.iterationsis the only supported option, but you're welcome to expand on this code and test others!termination/max_iterationsis necessary for theiterationstermination criterion and gives the number of generations that PSO should go through.
threadsis the number of threads used by themultiprocessingpool.topologygives the topology of the particle communication network. See above for more info!
Below you can run PSO on a simple function! The functions below are common benchmark functions, to learn more about each function, click the link:
- Eggholder - Non-convex
- Michalewicz (michal) - Non-convex
- Noisey Paraboloid (this is the paraboloid function over $[-10,10]^{2}$ but with a uniform random number between (-10,10) added to the result to introduce randomness) - Noisey
- Paraboloid/Sphere - Convex
- Rastrigin - Non-convex
- Shubert - Non-convex
To add more functions like those seen on Wikipedia and this site.
Note: You may not get the true minimum value from PSO, that is normal and not a bug. With the exception of the paraboloid, these are non-convex functions which are hard to optimize.
# create dropdowns for algorithm parameters
# feel free to adjust the values on the sliders/dropdowns!
func_dropdown = ipywidgets.Dropdown(
options=get_standard_funcs(),
description = "Cost Func",
value=noisey_paraboloid
)
generations_slider = ipywidgets.IntSlider(
value=36,
min=1,
max=120,
step=1,
description="N Generations"
)
part_slider = ipywidgets.IntSlider(
value=20,
min=1,
max=100,
step=1,
description='N Particles'
)
topology_dropdown = ipywidgets.Dropdown(
options=[ "fullyconnected", "ring", "vonNeumann" ],
description="Topology",
value="ring"
)
display(func_dropdown,generations_slider,part_slider,topology_dropdown)
# pass the arguments into the PSO function and run it
args = {
"gif" : "True",
"headless" : "False",
"max_velocity" : "inf",
"metric" : "rmse",
"output_dir" : "",
"particles" : part_slider.value,
"seed" : "None",
"threads" : 1,
"topology" : topology_dropdown.value,
"termination": {
"termination_criterion" : "iterations",
"max_iterations" : generations_slider.value
},
"function": {
"dim_description" : "None",
"dimension" : 2,
"function" : func_dropdown.value.__name__
}
}
pprint(args)
swarm = PSO(func_dropdown.value, get_bounds(func_dropdown.value,2), args)
print("True min is {} at {}".format(*get_global_minima(swarm.costFunc, 2)))
print("\nThe results can found at the run's output directory: {}".format(swarm.output_path))
print("\nThe log for the run can be found at {}. Here is small preview:".format(swarm.log_file))
with open(swarm.log_file) as myfile:
for i in range(3):
print(next(myfile))
What am I looking at here?¶
Above:
- The first output above is the parameters we are passing into the PSO function.
- Next, you should see a table that describes the generation of the algorithm the global best error (lowest error encountered by any particle), and the position that produced the error.
- At the end of the table, you will see the word "FINAL" which gives the best position and minimum error achieved over the run of the algorithm.
- Next, the output director is printed in case you want to explore the results yourself.
- Lastly, we print out the location of the log file along with the first 3 lines of it, in case you want to explore that.
Below:
- The next cell below plots the neighbor graph of the particles using Networkx.
- Secondly, we load the CSV result and show you the head of it so you can see what the results look like.
- Third, we show the surface and particles over the run of the algorithm.
# plot the neighbor graph
G = nx.from_numpy_array(swarm.neighbor_graph, create_using=nx.DiGraph)
nx.draw(G)

This is the CSV file that holds information on the position and error of each particle throughout the run.
# showing the result CSV created
result_csv = pd.read_csv(swarm.csv_out.name)
result_csv.head()
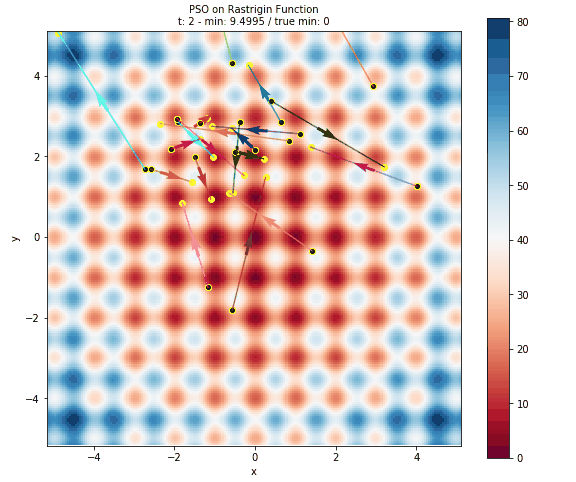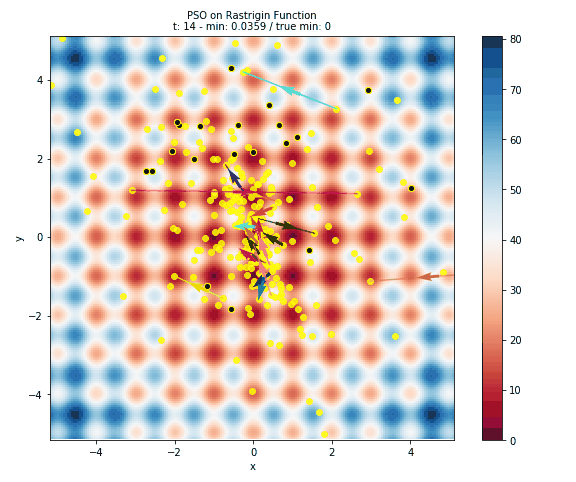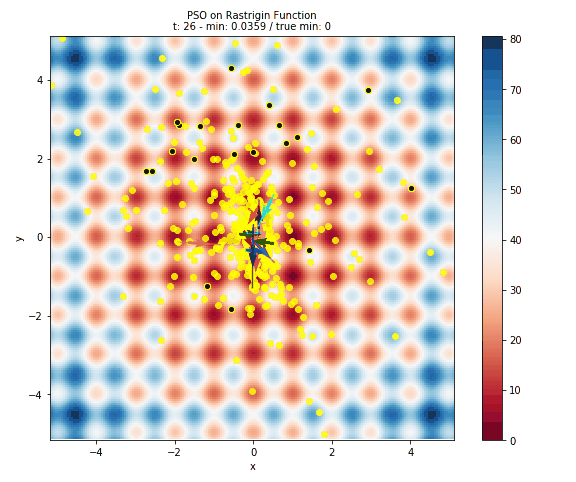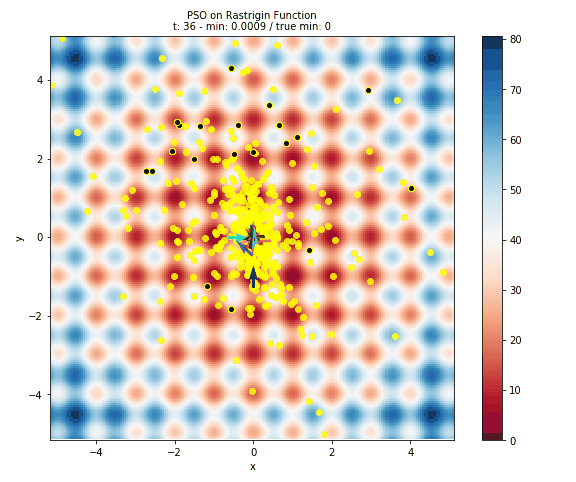
Here is plot of the surface, with arrows representing the particles flying around the space.
- The surface is colored based on the error at the position. This is done by evaluating 40,000 points in the space (controlled by the
granularityargument ofplot_surface). Obviously this is only useful for illustrative purposes and not at all feasible for computationally intensive models. - The black dots with the yellow halo represents the initial positons of the particles.
- The yellow dots represent all of the positions evaluated by PSO.
- The arrows are colored to help distinguish particles and show how a particle has travelled throughout the run of the algorithm.
# plot the surface of the function with particles
Image(filename=os.path.join(swarm.output_path, "surface.png"))

Below you can see a gif of the particles moving around your space! Just as in above, the surface is colored based on error, the black dots represent initial positions, the yellow dots represent positions evaluated, and arrows show the velocity of particles through space. This is created by plotting the state of the algorithm at each interation and compiling the images together into a gif using imageio.
# plot the gif created by the algorithm
Image(filename=os.path.join(swarm.output_path, "movie.gif"))
Adding Your Own Model¶
Adding a Simple Function¶
Adding models/functions is relatively simple. Everything is controlled by cost_funcs/info.py. This file imports all of the cost functions, defines the bounds of each function, the name, and keeps track of the global minima (if known). To add your own simple function you'd like to test here, you can follow these steps:
Add your function in
cost_funcs/standard.py. There are many other examples in thecost_funcs/standard.pyfile if you get confused, but here are the basic steps:- Each function takes the argument
argswhich is a dictionary and the position vector is stored inargs["x"]. This allows us to pass other information to the function if necessary. - Every function is assumed to return a tuple with the first element being the value of the function at
args["x"]and the second element exists in case you want to pass other information out of the function, but for a simple function just returnNone. - To see that function in the dropdown above, you will also want to add the function to the
funcslist inget_standard_funcs()at the bottom of the file.
- Each function takes the argument
- Add the information in
cost_funcs/info.py. This file defines three basic functions that give information on functions:get_boundswhich returns the bounds for a function. This is a list of tuples of the form [($\min x_{1}, \max x_{1}),\cdots, (\min x_{n}, \max x_{n}$)].get_function_namewhich returns a string that is the name of the function. This name is used in plotting.get_global_minimawhich returns a tuple (global min,tuple position of global min). This information is only used to plot the global min and its location at the end of the PSO run so you can compare. If this is not known, you can return (any int,None).
Adding a More Complex Model¶
Now that you know how to add a basic function, we can discuss a bit about how to add a more complex model. This is how I evaluate the ABM when using PSO. Rather than defining it in cost_funcs/standard.py you can put the model in its own python file and copy that file to the cost_funcs folder. The ABM can be seen in cost_funcs/JeonModelSimple.py. Somewhere in the file, define the function in the same format as above: it should take a dictionary as the input with input["x"] containing the parameters. This can be seen in the kang_simple function at the bottom of cost_funcs/JeonModelSimple.py.
Next, import the model into cost_funcs/info.py and define the bounds, name, and minima as discussed above. To run PSO on your model, you can just name the function under function/function in the JSON parameters and also add your function to the main function in the PSO. There are many examples in the main function on how to do this, but basically you are adding an if statement that checks the name of the function supplied in the JSON file and passes the correct function to the PSO class. I highly recommend running the model on HPC if it is computationally intensive.
Running from the Command Line/HPC¶
The code works from the command line if you specify the path to the params JSON. This is how it was used on cyberinfrastructure to evalue the spatially-explicit agent-based model. If you want to edit the parameters, simply edit the test.json file or create a new json file and specify that after the --params flag.
!python3 PSO.py --params test.json
How do I use this on HPC?¶
Using PSO for spatially-explicit ABMs, I wasn't able to to do that on my laptop and had to use HPC, this work took months of work on a large multi-node cluster! See the Adding Your Own Model section if you'd like to use PSO on your own model. Assuming you have this repo cloned on your HPC, a sample BATCH file might look like:
#SBATCH -n 12
#SBATCH --time=240:00:00
#SBATCH --mem-per-cpu=600
#SBATCH --mail-type=FAIL
#SBATCH --mail-type=END
#SBATCH --mail-user=<your email>
module purge
module use <module path>
module load anaconda3
python3 swarm.py --params ${PARAM} -s ${SEED}Of course, you may need to change this based on file locations, the number of processors you want to use, the memory requirements of your model, etc. If you want to run the algorithm for a variety of parameters/seeds, you can use a bash script like the one below to submit a set of jobs:
PARAMS=( "test1.json" "test2.json" )
for PARAM in "${PARAMS[@]}"; do
for SEED in $(seq 0 4); do
export SEED
export PARAM
sbatch PSO.batch
echo "Job ${PARAM}, ${SEED} submitted"
sleep 5 # pause to be kind to the scheduler
done
doneAgain, the script above is an example, you will likely have to make some changes to get it to work for you.
Spatially Explicit ABMs¶
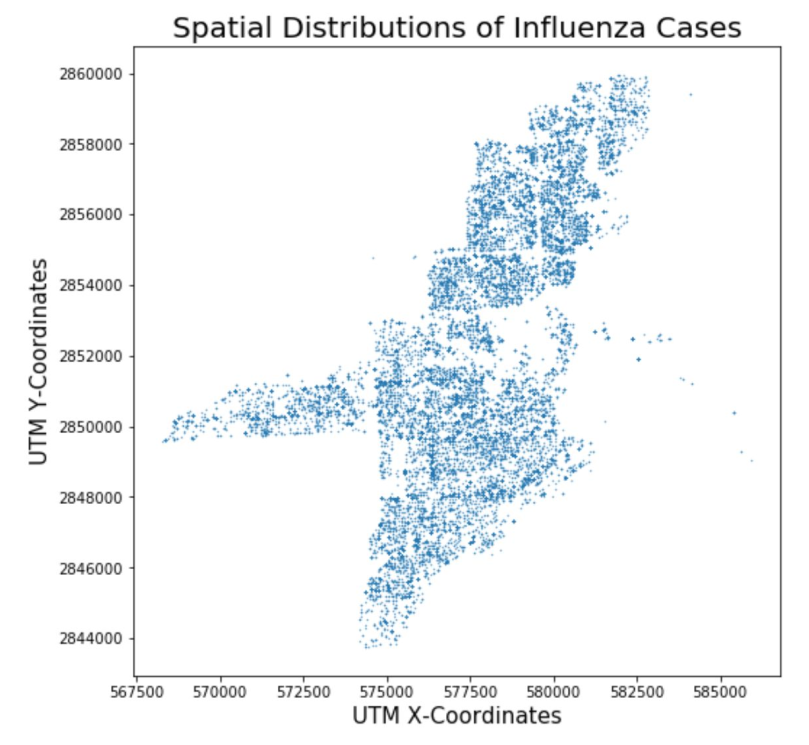
Our interest in PSO is for calibrating spatially-explicit agent-based models (ABMs). In particular, we chose a model of influenza transmission developed by Jeon-Young Kang. A notebook for this model is available on CyberGISX as well if you'd like to explore the model more indepth. The notebook uses data from the Queene Anne neighborhood of Seattle, but this repository contains data for a Miami if you'd like to run the model for Miami.
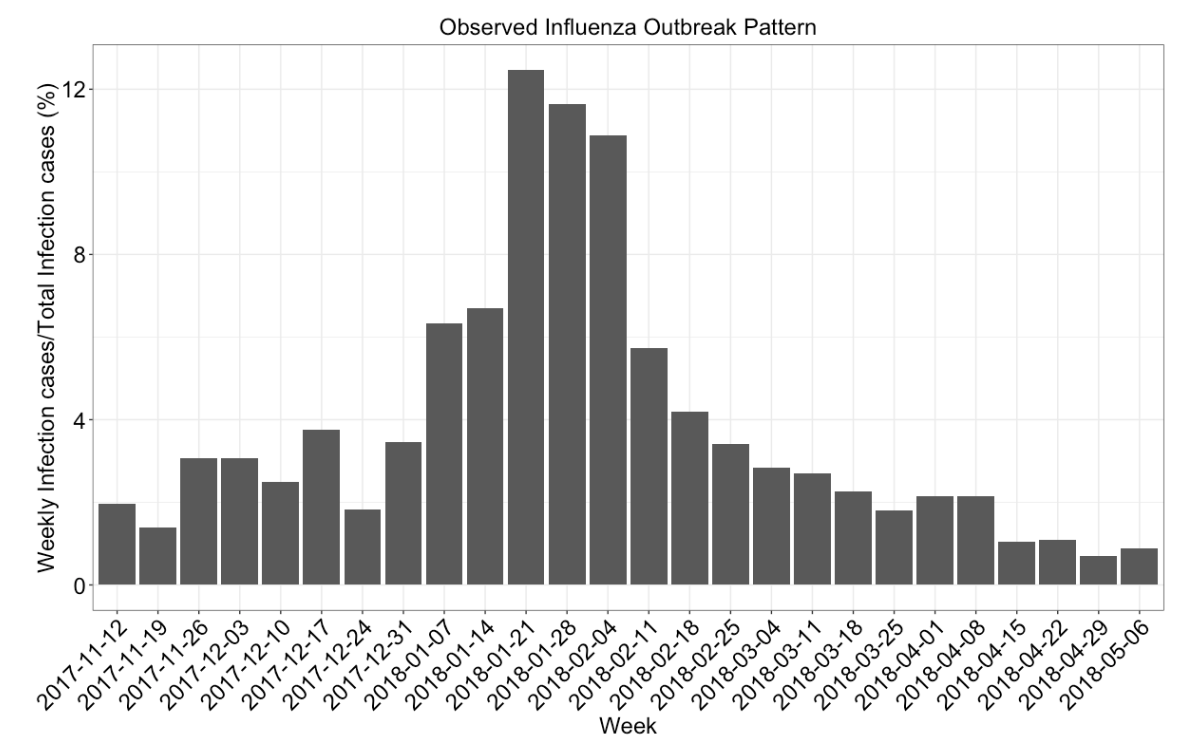
Calibrating spatially-explicit ABMs often depend on the concept of pattern-oriented validation. Pattern-Oriented Validation is based on Pattern-Oriented Modeling (POM) which seeks to replicate observed patterns using simulation. In the case of the influenza model, the pattern is the curve describing the number of cases over a flu season and we calibrate by getting the simulated curve as close as possible to this line. For our model, we were able to obtain influenza case data from the Florida Department of Health to validate.
An example JSON to run the PSO algorithm using the SEIR model can be found in seir_test.json:
NOTE: The spatially explicit ABM can take 30-120 minutes per run meaning that a single generation with 20 particles can take 10-40 hours per generation. It is not recommended to do this on here, but rather on cyberinfrastructure with a large number of threads to speed this up.
!cat seir_test.json
The function dictionary here shows how you can pass information to the cost function. In the example above, we are telling the kang_simple SEIR function to use data for the city of Miami and run the model for 154 days. This also shows you can use the dim_description option to label the parameters being swarmed on.
Learn More!¶
PSO¶
Overview / Introductory Papers¶
- Defining a Standard for PSO
- Particle swarm optimization
- Particle swarm optimization: developments, applications and resources
- Particle Swarm Optimization: An Overview
Selected Applications¶
- A hybrid particle swarm/ant colony algorithm for the classification of hierarchical biological data
- A particle swarm optimization-based heuristic for scheduling workflow applications in cloud computing environments
- Image classification using chaotic particle swarm optimization
- Particle swarm optimization: basic concepts, variants and applications in power systems
- Particle swarm optimization in wireless-sensor networks: A brief survey
Calibrating Spatially-Explicit ABM¶
- Pattern-Oriented Validation and Sensitivity Analysis Methods for Spatially Explicit Agent-Based Models
- Using multiple scale space-time patterns in variance-based global sensitivity analysis for spatially explicit agent-based models
- Using multiple scale spatio-temporal patterns for validating spatially explicit agent-based models