Spatial Partitioning Algorithm for Scalable Travel-time Computation (SPASTC): Illinois¶
Author: Alexander Michels
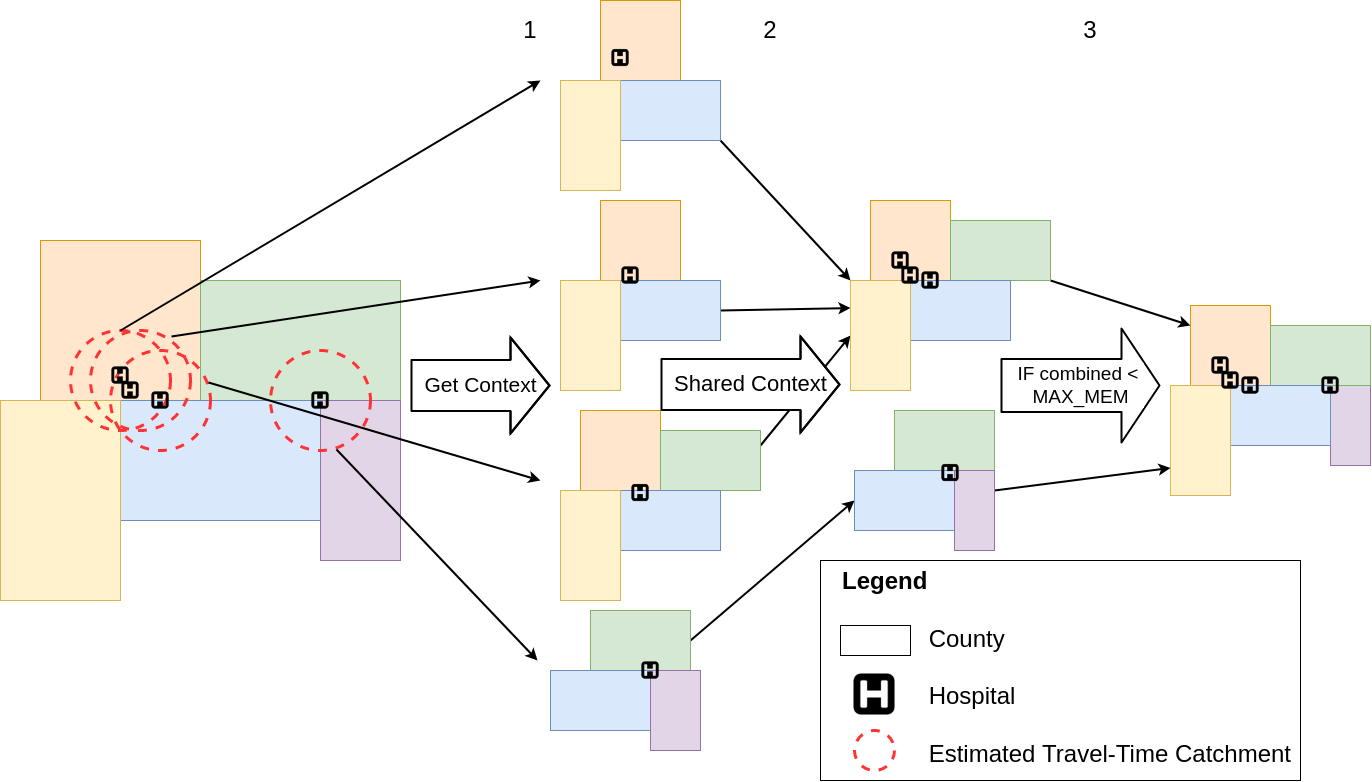
Image: Overiew of the SPASTC algorithm
Repo Author: Alexander Michels
Paper Authors: Alexander Michels, Jinwoo Park, Jeon-Young Kang, and Shaowen Wang
Paper: Published in IJGIS (doi: 10.1080/13658816.2024.2326445)
Paper Abstract:
We present a Spatial Partitioning Algorithm for Scalable Travel-time Computation (SPASTC). Calculating travel-time catchments over large spatial extents is com- putationally intensive, with previous work limiting their spatial extent to mini- mize computational burden or overcoming the computational burden with advanced cyberinfrastructure. SPASTC is designed for domain decomposition of travel-time catchment calculations with a user-provided memory limit on computation. SPASTC realizes this through spatial partitioning that preserves spatial relationships required to compute travel-time zones and respects a user-provided memory limit. This al- lows users to efficiently calculate travel-time catchments within a given memory limit and represents a significant speed-up over computing each catchment separately. We demonstrate SPASTC by computing spatial accessibility to hospital beds across the conterminous United States. Our case study shows that SPASTC achieves signifi- cant efficiency and scalability making the computation of travel-time catchment up to 51 times faster.
In this notebook, we will walk through the SPACTS algorithm for calculating travel-time catchments of hospitals in Illinois.
from collections import Counter
import copy
from disjoint_set import DisjointSet
import geopandas as gpd
import itertools
import math
import matplotlib.pyplot as plt
import multiprocessing as mp
import networkx as nx
from networkx.algorithms.operators.binary import compose as nx_compose
from numbers import Number # allows for type hinting of numerics
import numpy as np
import os
import pandas as pd
import time
import tqdm
from typing import Iterable, List, Set, Tuple
Parameters¶
For simplicity, I have put the parameters/file paths/etc. in this big PARAMS dict. Not all of the parameters/options below are relevant, but they are all given because I used a large PARAM json when running my experiments.
A brief overview of the sections:
- access - parameters related to the accessibility calculation. You'll see projection to do the final plot in and weights to use for E2SFCA
- compute - computational parameters, specifically maximum memory and number of threads for certain sections that are parallelized
- graphml - parameters related to the OSMnx networks, stored in graphml files. Unfortunatly, Github doesn't allow for storing hundreds of gigabytes of graphml files, but the
scriptsfolder can help you obtain the graphs yourself. - output - used for configuring outputs like figure size
- pop - information relating to population data
- region - parameters relating to clustering regions and calculating travel-time catchments
- resource - parameters relating to the resource data (in our case hospitals
PARAMS = {
"access": {
"weights": [1.0, 0.68, 0.22],
"projection": "EPSG:4326"
},
"compute": {
"max_memory" : 8,
"threads" : 8
},
"graphml": {
"geo_unit_key" : "GEOID",
"geo_unit_shapefile" : "../data/geodata/counties/ILCounties/ILCountyShapefile.shp",
"dir" : "../data/graphml/ilcounties/graphml",
"name_format" : "0500000US{}.graphml",
"memory_csv" : "../data/memory_df/USCounty-MemoryUsage.csv",
"memory_column" : "Memory Usage (GB)",
"memory_key" : "GEOID"
},
"output": {
"figsize": [12, 18]
},
"pop" : {
"file": "../data/pop/illinois/SVI2018_IL_tract.shp",
"pop_field": "E_TOTPOP",
"pop_key": "FIPS"
},
"region" : {
"batch_size": 4,
"buffer": 64374,
"catchment_file_pattern": "resource_catchments_{}distance.geojson",
"catchment_how": "convexhull",
"distances": [600, 1200, 1800],
"dir": "../data/regions/Illinois",
"projection" : "ESRI:102003"
},
"resource" : {
"key": "ID",
"resource": "BEDS",
"shapefile" : "../data/hospitals/illinois/IllinoisHospitals.shp"
}
}
Data¶
Let's load the hospital data! We will also perform a few checks:
- check that our "key" is actually unique so we can identify each hospital uniquely
- project our data to Contiguous Albers Equal Area Conic Projection: https://epsg.io/102003
- print out the projection and number of hospitals
- view the data with head()
resources = gpd.read_file(PARAMS["resource"]["shapefile"])
assert resources[PARAMS["resource"]["key"]].is_unique
resources = resources.to_crs(PARAMS["region"]["projection"])
print("The geometry is {}".format(resources.crs))
print("There are {} resources represented".format(len(resources)))
resources.head()
We can also visualize the data by plotting it with Geopandas:
resources.plot(figsize=PARAMS["output"]["figsize"])

Our method for calculating travel-time catchments relies on clustering spatial units (in our case counties) together into "regions." Doing this requires that we have our OSMnx network pulled by county, and data on the geographic bounds of counties so we can see how they relate to our hospitals.
Here we load the shapefile for counties, drop any duplicates, and project the data.
county_shapefiles = gpd.read_file(PARAMS["graphml"]["geo_unit_shapefile"])
county_shapefiles.drop_duplicates(inplace=True, subset=[PARAMS["graphml"]["geo_unit_key"]])
county_shapefiles = county_shapefiles.to_crs(PARAMS["region"]["projection"])
print("There are {} counties represented".format(len(county_shapefiles)))
county_shapefiles.head()
Let's plot the data with Geopandas again:
county_shapefiles.plot(figsize=PARAMS["output"]["figsize"])

Our method clusters the road network pieces up to a given memory limit. To do this, we need information on the memory usage of each piece of the network. This was generated with a script in the scripts directory if you're interested on the details!
memory_df = pd.read_csv(PARAMS["graphml"]["memory_csv"])
# cast ID to string
memory_df[PARAMS["graphml"]["memory_key"]] = memory_df[PARAMS["graphml"]["memory_key"]].astype(str)
# left pad the string with zeros up to 5 digits
memory_df[PARAMS["graphml"]["memory_key"]] = memory_df[PARAMS["graphml"]["memory_key"]].str.pad(5, side="left", fillchar="0")
print("There are {} counties represented".format(len(memory_df)))
memory_df.drop_duplicates(inplace=True, subset=[PARAMS["graphml"]["memory_key"]])
memory_df.head()
Calculate Primary Regions¶
This step uses an over-estimate of the driving-time catchment to determine the pieces of the network necessary for calculating each hospital's travel-time catchment. Since our projection is in meters, we set the buffer radius to ~64km whih is ~40miles. This will contain a 30 minute driving-time catchment even if the driver is going straight at 80mph for the entire 30 minutes.
Let's plot the buffers:
def calculate_buffers(gdf: gpd.GeoDataFrame, buffer: Number) -> gpd.GeoDataFrame:
"""
Makes a deepcopy with geography replaced with buffers.
Args:
gdf: GeoDataFrame
buffer: Number, size of the buffer (in gdf's CRS units)
Returns:
GeoDataFrame, copy of gdf with buffers in geometry
"""
buffers = gdf.copy(deep=True)
buffers["geometry"] = buffers.geometry.buffer(buffer)
return buffers
buffers = resources.copy(deep=True)
buffers = calculate_buffers(resources, PARAMS["region"]["buffer"])
buffers.plot(alpha=0.1, figsize=PARAMS["output"]["figsize"])

Using this information we can calculate the overlap between each hospital's buffer and the counties:
def calculate_primary_regions(resources: gpd.GeoDataFrame, resource_key: str, buffer_size: float,
spatial_units: gpd.GeoDataFrame, spatial_units_key: str,
disable_tqdm=False) -> dict:
"""
For each shape in `buffers`, we calculate it's overlap with the shapes in `spatial_units`.
Args:
resources (gpd.GeoDataFrame): Geodataframe of resources (hospitals)
resource_key (str): key/ID field for resources/buffers
buffer_size (float): size of buffers for resources
spatial_units (gpd.GeoDataFrame): Geodataframe of spatial units (counties)
spatial_units_key (str): key/ID field for spatial_units
disable_tqdm (bool): whether or not to disable the tqdm progress bar
Returns:
Dictionary of id -> set of keys from spatial_units
Raises:
Assertion that the length of each overlap list is greater than zero
Todo:
* Better error handling/checking for len >= 0
"""
buffers = resources.copy(deep=True)
buffers["geometry"] = buffers.geometry.buffer(buffer_size)
# resource to spatial unit dict
region2sudict = dict()
for index, row in tqdm.tqdm(buffers.iterrows(), desc="Calculating primary regions", disable=disable_tqdm,
position=0, total=len(buffers)):
in_buffer = spatial_units[spatial_units.intersects(row["geometry"])]
_geoids = set(list(in_buffer[spatial_units_key]))
region2sudict[row[resource_key]] = _geoids
return copy.deepcopy(region2sudict)
resource_census_unit_overlap_dict = calculate_primary_regions(resources,
PARAMS["resource"]["key"],
PARAMS["region"]["buffer"],
county_shapefiles,
PARAMS["graphml"]["geo_unit_key"])
# resource_census_unit_overlap_dict
This dictionary can be extremely long, so let's look at a small slice of it:
dict(list(resource_census_unit_overlap_dict.items())[0:5])
This method performs a partitioning of the hospitals (each hospital in one group) and clustering of the counties (counties can be in more than one group). After this step we have a partition of singletons meaning that each hospital is in a group by itself. This algorithm also gives us a one-to-one relationship between each partition of hospitals and cluster of counties where the group of counties is sufficient for calculating the travel-time catchments for the corresponding group of hospitals.
A county network will be loaded once for each cluster it is in. Let's visualize how many times each county network is loaded if we used this initial partition!
First we need to count how many times each county is included in a cluster and make that into a dataframe, then we can merge that to our geodataframe and plot:
def viz_nregions(region2sudict: dict, spatial_units: gpd.GeoDataFrame, su_key: str,
output_column: str = "nregions") -> gpd.GeoDataFrame:
"""
Function for visualizing the number of regions each spatial unit is in at a given step of the
process.
Args:
region2sudict: dict, maps regions to the census units that make up the region
spatial_units: GeoDataFrame of spatial units
su_key: str, key for the spatial_units GeoDataFrame
output_column: str, column to write result to
Returns:
copy of spatial_units with `column` having the number of regions each spatial unit is in
"""
region_counter = Counter()
for region_id, geoids in region2sudict.items():
for geoid in geoids:
region_counter[geoid] += 1
# convert counter to dataframe for merging
region_df = pd.DataFrame(region_counter.items(), columns=[su_key, output_column])
output_gdf = spatial_units.copy(deep=True)
# drop our output column if it already exists
output_gdf = output_gdf.drop(columns=output_column, errors='ignore')
output_gdf = output_gdf.merge(region_df, how="left", on=su_key)
return output_gdf
primary_regions = viz_nregions(resource_census_unit_overlap_dict, county_shapefiles,
PARAMS["graphml"]["geo_unit_key"])
primary_regions.plot(column='nregions', figsize=PARAMS["output"]["figsize"], legend=True)

Merging by Set Relations (Shared Spatial Context)¶
Now that we know the necessary counties for each hospital, we want to combine them by shared spatial context. Since we have the spatial context given by a list of counties, we can do this by just comparing the sets of counties. If $A\subseteq B$ which means "A is a subset of B", then A's list of counties are included in B's so we can do the travel-time calculation for A and B with B's set of counties! Note that this means these merges don't add to the memory requirements: B's counties would have to be loaded regardless, but calculating A and B together let's us avoid loading the counties twice.
Let's see what hospitals we should merge:
def calculate_secondary_regions(region2sudict: dict, resources: gpd.GeoDataFrame,
resource_key: str) -> Tuple[dict, dict]:
"""
Calculates the secondary regions by their set relations/shared spatial context.
Args:
region2sudict (dict): maps resources to the spatial units that make up their primary region
resources (gpd.GeoDataFrame): GeoDataFrame of resources
resource_key (str): key/ID in resources
Returns:
Tuple of dicts: updated region2sudict (region -> spatial units) and resource2regiondict
(resource -> region)
"""
_resources = list(resources[resource_key])
resource_disjoint_set = DisjointSet() # create a disjoint set
for r in _resources:
resource_disjoint_set.find(r) # add the stuff to the disjoint set
for key in tqdm.tqdm(_resources, desc="Merging by Set Rel", position=0):
val = set(region2sudict[key])
for okey in _resources:
oval = set(region2sudict[okey])
if val == oval: # sets are same
resource_disjoint_set.union(okey, key)
elif oval.issubset(val):
resource_disjoint_set.union(okey, key)
unioned_region = region2sudict[key].union(region2sudict[okey])
region2sudict[key] = unioned_region
region2sudict[okey] = unioned_region
# record map of resource to region (i.e. reverse of ds dictionary)
newregion2sudict, resource2regiondict = dict(), dict()
for key, val in tqdm.tqdm(resource_disjoint_set.itersets(with_canonical_elements=True),
desc="Updating maps", position=0):
newregion2sudict[key] = region2sudict[key]
for resource in val:
resource2regiondict[resource] = key
return newregion2sudict, resource2regiondict
region2cu, resource2region = calculate_secondary_regions(resource_census_unit_overlap_dict,
resources,
PARAMS["resource"]["key"])
# region2cu
# resource2region
We can again plot how many clusters each county is in/how many times each county would have to be loaded:
secondary_regions = viz_nregions(region2cu, county_shapefiles, PARAMS["graphml"]["geo_unit_key"])
secondary_regions.plot(column='nregions', figsize=PARAMS["output"]["figsize"], legend=True)

Merging by Memory¶
Now that we have done merging by set relations, further merges may increase the overall memory requirements so we have to consider memory usage from now on. Below are three functions that help us do that:
def calculate_memory_usage(memory_df: pd.DataFrame, memory_key: str, memory_col: str, list_of_ids: List[str]) -> Number:
"""
Calculates the memory usage the shapefiles specified by a list of ids.
Args:
memory_df: DataFrame mapping memory_key to memory_col (spatial unit ID -> memory usage)
memory_key: str, key/ID in memory_df
memory_col: str, amount of memory usaged by data in spatial unit
list_of_ids: list of str, ids to sum memory usage for
Returns:
Number, sum of memory usages for all ids
"""
return sum([float(memory_df.loc[(memory_df[memory_key] == _id), memory_col]) for _id in list_of_ids])
def calculate_memory_difference(memory_df: pd.DataFrame, memory_key: str, memory_col: str, set_a: Iterable[str], set_b: Iterable[str]) -> Number:
"""
Calculates the memory usage of the difference between two iterables of spatial unit IDs.
Args:
memory_df: DataFrame mapping memory_key to memory_col (spatial unit ID -> memory usage)
memory_key: str, key/ID in memory_df
memory_col: str, amount of memory usaged by data in spatial unit
set_a: iterable of spatial units to subtract from
set_b: iterable of spatial units to subtract
Returns:
Number, memory usage of A - B
"""
set_a, set_b = set(set_a), set(set_b)
_diff = set_a.difference(set_b)
return calculate_memory_usage(memory_df, memory_key, memory_col, _diff)
def get_max_memory_usage(memory_df: pd.DataFrame, memory_key: str, memory_col: str, region2sudict: dict) -> Number:
"""
Calculates the maximum memory requirement for all secondary regions.
Args:
memory_df: DataFrame mapping memory_key to memory_col (spatial unit ID -> memory usage)
memory_key: str, key/ID in memory_df
memory_col: str, amount of memory usaged by data in spatial unit
region2sudict: dict, dictionary mapping (resource -> spatial units)
Returns:
float, maximum memory usage for a set of regions
"""
return max([calculate_memory_usage(memory_df, memory_key, memory_col, region2sudict[key]) for key in region2sudict.keys()])
While we are operating under memory limits, the memory limit is not feasible unless we can load all secondary regions within the limit. Why?
Because secondary regions are by design the set of counties required for at least one hospital corresponding to that region. So if our memory limit can't handle that set of counties, we can't calculate that hospital's travel-time catchment within the memory limit.
With that in mind, let's see the maximum memory usage for the current regions:
memory_usage_so_far = get_max_memory_usage(memory_df,
PARAMS["graphml"]["memory_key"],
PARAMS["graphml"]["memory_column"],
region2cu)
print(memory_usage_so_far)
The next line asserts that our memory limit is greater than our current memory usage:
assert memory_usage_so_far < PARAMS["compute"]["max_memory"]
Now that we have passed that bar, we can start merging our regions by memory usage. This uses a greedy algorithm which combined regions with the smallest memory difference until no more merges can be made. This uses the following functions:
def merge_regions(region_a, region_b, region_to_census_units_dict, resource_to_region_dict):
"""
Merge two regions in the region_to_census_units_dict and resource->region dict (res2reg_dict)
Args:
region_a: id of region
region_b: id of region
region_to_census_units_dict: dictionary of regions -> census units
resource_to_region_dict: dictionary of resource -> region
Returns:
tuple of dicts: (updated region_to_census_units_dict, updated resource_to_region_dict)
"""
region_to_census_units_dict[region_a] = region_to_census_units_dict[region_a].union(region_to_census_units_dict[region_b])
del region_to_census_units_dict[region_b]
# set resources to region_a
region_b_resources = [key for key, item in resource_to_region_dict.items() if item == region_b]
for resource in region_b_resources:
resource_to_region_dict[resource] = region_a
return region_to_census_units_dict, resource_to_region_dict
def regions_disjoint(region2sudict: dict, region_a: str, region_b: str) -> bool:
"""
Tests if two regions are disjoint.
Args:
region2sudict: dictionary of regions -> spatial units
region_a: id of a region
region_b: id of a region
Returns:
boolean, if the set of file ids (counties) is disjoint
"""
return set(region2sudict[region_a]).isdisjoint(region2sudict[region_b])
def minimum_combined_memory_region(memory_df: pd.DataFrame, memory_key: str, memory_col: str,
region2sudict: dict, region_a: str) -> Tuple[Number, str, str]:
"""
Finds the region (_to_merge_b) that minimizes the combined memory of region_a and _to_merge_b.
Args:
memory_df: Dataframe that maps region id to memory usage
memory_key: key/ID to memory_df
memory_col: field in memory_df with memory usage
region2sudict: dictionary from region id -> list of file ids (counties)
region_a: id of a region
Returns:
tuple: (float: memory usage, region_a, id of region that has minimum memory difference)
"""
regions = list(region2sudict.keys())
region_a_mem = calculate_memory_usage(memory_df, memory_key, memory_col, region2sudict[region_a])
_merge_mem, _to_merge_b = 1000000000, -1
for region_b in regions:
if region_a != region_b and not regions_disjoint(region2sudict, region_a, region_b):
_mem_diff = calculate_memory_difference(memory_df, memory_key, memory_col,
region2sudict[region_b], region2sudict[region_a])
if _mem_diff < _merge_mem:
_merge_mem, _to_merge_b = _mem_diff, region_b
return (float(_merge_mem + region_a_mem), region_a, _to_merge_b)
def calculate_final_regions(region2sudict: dict, resource2regiondict: dict,
max_mem: Number, threads: int, memory_df: pd.DataFrame,
memory_key: str, memory_col: str, verbose: bool = False) -> Tuple[dict, dict]:
"""
Calculates final regions by combining regions by memory usage.
Args:
region2sudict: dictionary of regions -> spatial units
resource2regiondict: dictionary of resource -> region
max_mem: memory usage not to exceed
threads: how many threads to use when finding minimum_combined_memory_region for each region
memory_df: Dataframe that maps region id to memory usage
memory_key: key/ID to memory_df
memory_col: field in memory_df with memory usage
verbose (bool): whether or not to print all merges
Returns:
tuple of dicts, (updated region2sudict, updated resource2regiondict)
Raises:
assertion that max_mem is greater than required memory usage
"""
initial_number_of_regions = len(region2sudict)
how_many_chars = 12 # how many characters of region id to print
loop_counter = 0 # keep track of how many outer loops
done_combining = False
while not done_combining:
regions = list(region2sudict.keys())
_start = time.time() # for timing each iteration
with mp.Pool(processes=threads) as pool:
# calculate minimum combined memory region in parallel
results = pool.starmap(minimum_combined_memory_region, zip(itertools.repeat(memory_df),
itertools.repeat(memory_key),
itertools.repeat(memory_col),
itertools.repeat(region2sudict),
regions))
results = sorted(results, key=lambda tup: tup[0]) # sort by first element of tuple
nmerged = 0 # number of mergers this iteration
merged_this_iter = set() # keep track of regions we have merged with this iteration
if results[0][0] > max_mem: # all merges are too big
done_combining = True
for _merge_mem, _to_merge_a, _to_merge_b in results:
# memory is under the limit, the regions haven't been altered this run
if _merge_mem <= max_mem and _to_merge_a not in merged_this_iter and _to_merge_b not in merged_this_iter:
if verbose:
print(" New size: {:6.2f}, A: {}, B: {}".format(_merge_mem,
str(_to_merge_a).ljust(how_many_chars)[:how_many_chars],
str(_to_merge_b).ljust(how_many_chars)[:how_many_chars]))
nmerged += 1
merged_this_iter.add(_to_merge_a)
merged_this_iter.add(_to_merge_b)
region2sudict, resource2regiondict = merge_regions(_to_merge_a, _to_merge_b, region2sudict, resource2regiondict)
elif _merge_mem > max_mem:
break
print(f"(Iter: {loop_counter}) Time: {time.time() - _start:4.2f}, Merged {nmerged} regions")
loop_counter += 1
_dropped = initial_number_of_regions - len(region2sudict)
print(f"Dropped {_dropped} regions ({initial_number_of_regions}--->{len(region2sudict)})")
return copy.deepcopy(region2sudict), copy.deepcopy(resource2regiondict)
This can take a little while, but each iteration should be faster than the last:
region2cu, resource2region = calculate_final_regions(region2cu,
resource2region,
PARAMS["compute"]["max_memory"],
PARAMS["compute"]["threads"],
memory_df,
PARAMS["graphml"]["memory_key"],
PARAMS["graphml"]["memory_column"])
Let's again plot how many times each county is loaded with our final regions:
final_regions = viz_nregions(region2cu, county_shapefiles, PARAMS["graphml"]["geo_unit_key"])
final_regions.plot(column='nregions', figsize=PARAMS["output"]["figsize"], legend=True)

We can also visualize what these regions look like:
def viz_region_per_spatial_unit(region2sudict: dict, spatial_units: gpd.GeoDataFrame,
su_key: str, output_column: str = "region", nregions_column="nregions") -> gpd.GeoDataFrame:
"""
Plots the spatial units colored according to the region (or multiple) they are in.
Args:
region2sudict: dictionary mapping regions to the spatial units within it
spatial_units: GeoDataFrame of spatial units
su_key: str, key for the spatial_units GeoDataFrame
output_column: str, column to write result to
nregions_column: output column for the number of regions each spatial unit is in (`viz_nregions`)
Returns:
copy of spatial units with `column` having the region (or multiple) each spatial unit is in
"""
inverted_region_dict = dict()
for region_num, (region, counties) in enumerate(region2sudict.items()):
for county in counties:
inverted_region_dict[county] = f"Region {region_num}"
output_gdf = viz_nregions(region2sudict, spatial_units, su_key, output_column=nregions_column)
# drop our output column if it already exists
output_gdf = output_gdf.drop(columns=output_column, errors='ignore')
output_gdf = output_gdf.merge(pd.DataFrame(inverted_region_dict.items(), columns=[su_key, output_column]), how="left", on=su_key)
output_gdf.loc[output_gdf[nregions_column] > 1, output_column] = "Multiple"
return output_gdf
final_regions = viz_region_per_spatial_unit(region2cu, county_shapefiles, PARAMS["graphml"]["geo_unit_key"])
final_regions.head()
final_regions.plot(column='region',
categorical=True,
cmap='Spectral',
figsize=(18,10),
legend=True,
legend_kwds={'loc': 'lower right'})

primary_regions["logcount"] = np.log2(primary_regions["nregions"])
secondary_regions["logcount"] = np.log2(secondary_regions["nregions"])
final_regions["logcount"] = np.log2(final_regions["nregions"])
cbfont_size = 14
font_size = 24
size = (12, 16)
wspace = 0
hspace = 0.07
fontfamily = "TeX Gyre Termes Math"
_colormap = 'RdYlBu'
edgecolor="black"
null_color='grey'
plt.rcParams.update({'font.size': font_size, 'font.family': fontfamily})
fig, axes = plt.subplots(nrows=2, ncols=2, figsize=size)
for a in axes.flat:
a.set_xticklabels([])
a.set_yticklabels([])
a.set_axis_off()
a.margins(x=0, y=0)
fig.subplots_adjust(wspace=wspace, hspace=hspace)
#fig.suptitle("Clusters Per County")
vmax = max(primary_regions["logcount"])
vmin = 0
finalvmin = 1
finalvmax = max(final_regions["nregions"])
axes[0,0] = primary_regions.plot(column='logcount', cmap=_colormap, ax=axes[0,0], edgecolor=edgecolor,
missing_kwds=dict(color=null_color), vmin=vmin, vmax=vmax)
axes[0,0].set_title("a) Primary (log scale)", fontfamily=fontfamily, fontsize=font_size, loc='left') # increase or decrease y as needed
axes[0,1] = secondary_regions.plot(column='logcount', cmap=_colormap, ax=axes[0,1], edgecolor=edgecolor,
missing_kwds=dict(color=null_color), vmin=vmin, vmax=vmax)
axes[0,1].set_title("b) Secondary (log scale)", fontfamily=fontfamily, fontsize=font_size, loc='left') # increase or decrease y as needed
axes[1,0] = final_regions.plot(column='logcount', cmap=_colormap, ax=axes[1,0], edgecolor=edgecolor,
missing_kwds=dict(color=null_color), vmin=vmin, vmax=vmax)
axes[1,0].set_title("c) Final (log scale)", fontfamily=fontfamily, fontsize=font_size, loc='left') # increase or decrease y as needed
#cbar = fig.colorbar(im, ax=axes.ravel().tolist(), shrink=0.95)
axes[1,1] = final_regions.plot(column='nregions', cmap=_colormap, ax=axes[1,1], edgecolor=edgecolor,
missing_kwds=dict(color=null_color), vmin=finalvmin, vmax=finalvmax)
axes[1,1].set_title("d) Final (linear scale)", fontfamily=fontfamily, fontsize=font_size, loc='left') # increase or decrease y as needed
caxlog = fig.add_axes([0.05, 0.1, 0.03, 0.8])
smlog = plt.cm.ScalarMappable(cmap=_colormap, norm=plt.Normalize(vmin=vmin, vmax=vmax))
smlog._A = []
ticks = list(range(math.floor(vmin), math.ceil(vmax + 1)))
cbarlog = fig.colorbar(smlog, cax=caxlog, ticks=ticks)
cbarlog.ax.set_yticklabels([f"$2^{{{x}}}$" for x in ticks])
cbarlog.set_label("times each county is used (log scale)", labelpad=-70, rotation=270)
# cbarlogax = cbarlog.ax
# cbarlogax.text(-1.5, 2.5,"log scale", rotation=90)
caxlin = fig.add_axes([0.9, 0.1, 0.03, 0.8])
smlin = plt.cm.ScalarMappable(cmap=_colormap, norm=plt.Normalize(vmin=finalvmin, vmax=finalvmax))
smlin._A = []
ticks = list(range(finalvmin, math.ceil(finalvmax + 1)))
cbarlin = fig.colorbar(smlin, cax=caxlin, ticks=ticks)
cbarlin.ax.set_yticklabels([str(x) for x in ticks])
cbarlin.set_label("times each county is used (linear scale)", labelpad=2, rotation=90)
# cbarlinax = cbarlin.ax
# cbarlinax.text(3, 1.45,"linear scale", rotation=90)
fig.savefig(os.path.join(PARAMS["region"]["dir"], "ILClustering.jpg"), dpi=100, bbox_inches='tight')

Now that we have broken down our spatial extent into regions, we can calculate travel-time catchments. This can be a VERY time consuming process and requires OSMnx networks, so we recommend using a compute cluster. The steps are as follows:
- For each region, load and compose (networkx has this functionality) the counties.
- For each hospital in the region, calculate the egocentric network around the nearest OSM node to the hospital. To convert this into a polygon, calculate the convex hull around the nodes.