1 Geospatial Exploration and Resolution (GEAR) Lab, Department of Geography, College of Geosciences, Texas A & M University
2 GIResilience Lab, Department of Geography, College of Geosciences, Texas A & M University
3 Zachry Department of Civil and Environmental Engineering, College of Engineering, Texas A & M University
4 CyberGIS Center for Advanced Digital & Spatial Studies, University of Illinois at Urbana-Champaign
5 Department of Environmental Sciences, College of the Coast & Environment, Louisiana State University
* Corresponding author: lzou@tamu.edu
You can checkout the paper here: https://doi.org/10.48550/arXiv.2404.09463
Introduction¶
Resilience assessment and improvement have become increasingly important in today's world, where natural and man-made disasters are becoming more frequent and severe. Cities, communities, and organizations are recognizing the need to prepare for and mitigate the impacts of disasters and disruptions, and there is a growing body of research and practice on resilience assessment and improvement.
One significant research gap in this area is the lack of a customizable platform for resilience assessment and improvement. While there are many tools and frameworks available for assessing and improving resilience, they are often limited in their scope and applicability. Many of these tools are designed for specific types of hazards or sectors and may not be easily adapted to other contexts. Furthermore, many of these tools are proprietary and require significant resources to implement and maintain.
A customizable platform for resilience assessment and improvement would address these limitations by providing a flexible and adaptable framework that can be tailored to the needs and priorities of different users. Such a platform would allow users to customize the tools and metrics used for resilience assessment, as well as the interventions and strategies for resilience improvement. This would enable users to address specific challenges and opportunities in their context, and to leverage existing resources and knowledge to support resilience. By enabling users to tailor resilience assessment and improvement to their specific needs and priorities, such a platform would help to build more resilient communities, organizations, and systems, and contribute to a more sustainable and resilient future for all.
Resilience Inference Measurement Model¶
The Resilience Inference Measurement (RIM) model was developed by Dr. Nina Lam to measure disaster resilience of various units of the community, viz. individuals and organizations. It is based on the idea that resilience is dependent on adaptability as well as vulnerability, i.e., not just the ability to bounce back from adversity, but also the ability to adapt and thrive in the face of ongoing challenges and stressors. The RIM model is unique in that it evaluates resilience using empirical disaster measures such as threat, damage and recovery in line with the Sendai Framework, as well as taking on a holistic approach to measuring resilience, incorporating not only empirical factors but also the broader social and environmental context. This makes it a powerful tool for identifying areas of strength and weakness in resilience and for developing targeted interventions and strategies to build resilience in communities.
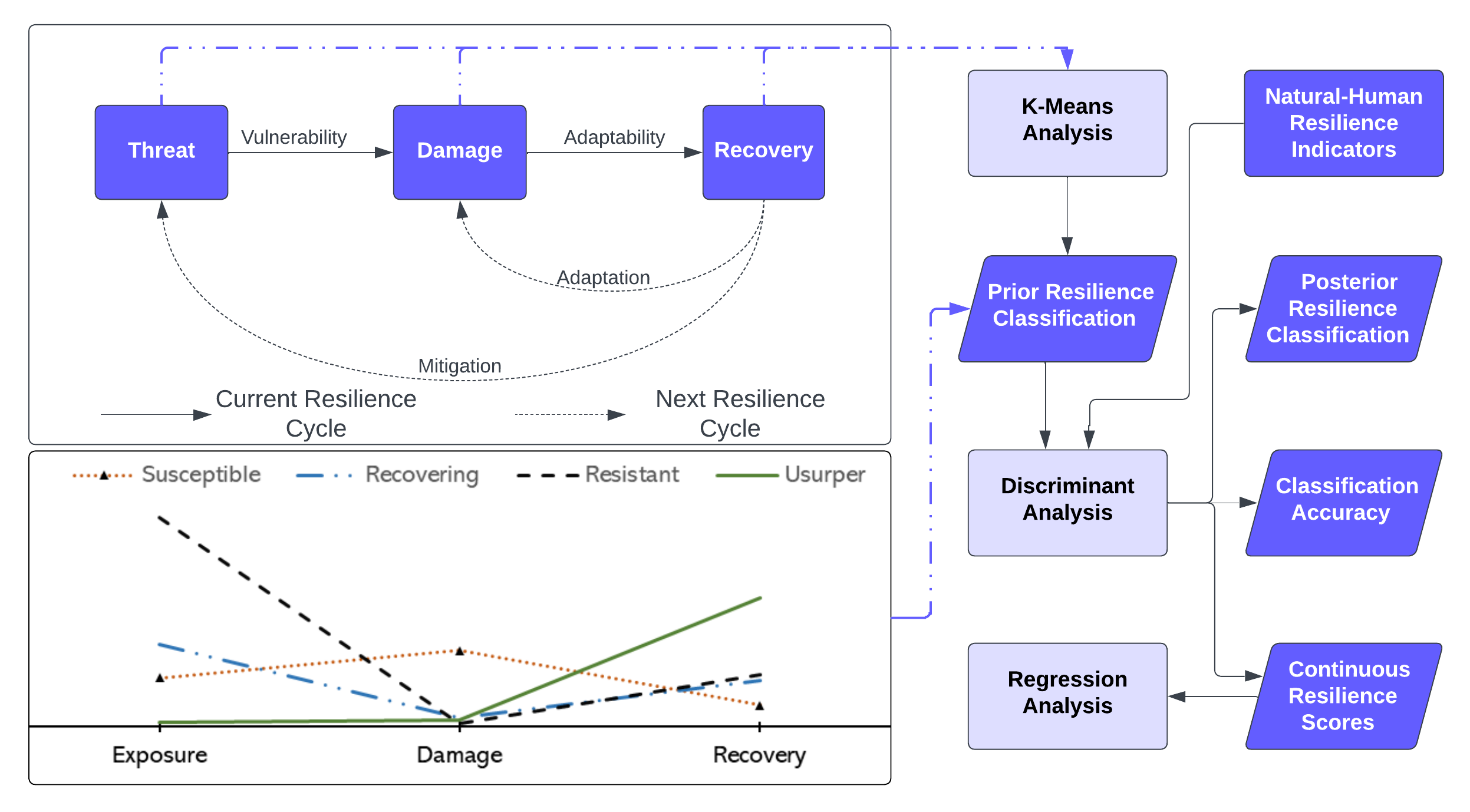
The above figure suggests the preliminary idea that in one resilience cycle vulnerability is dependent on exposure and damage, while adaptability is dependent upon the damage and recovery from the natural hazard. This goes into a feedback loop and updates itself in the next resilience cycle where mitigation procedures from recovery activities reduce exposure to the particular disaster while adaptation measures reduce future disaster damages.
Enhanced Customizable Framework¶
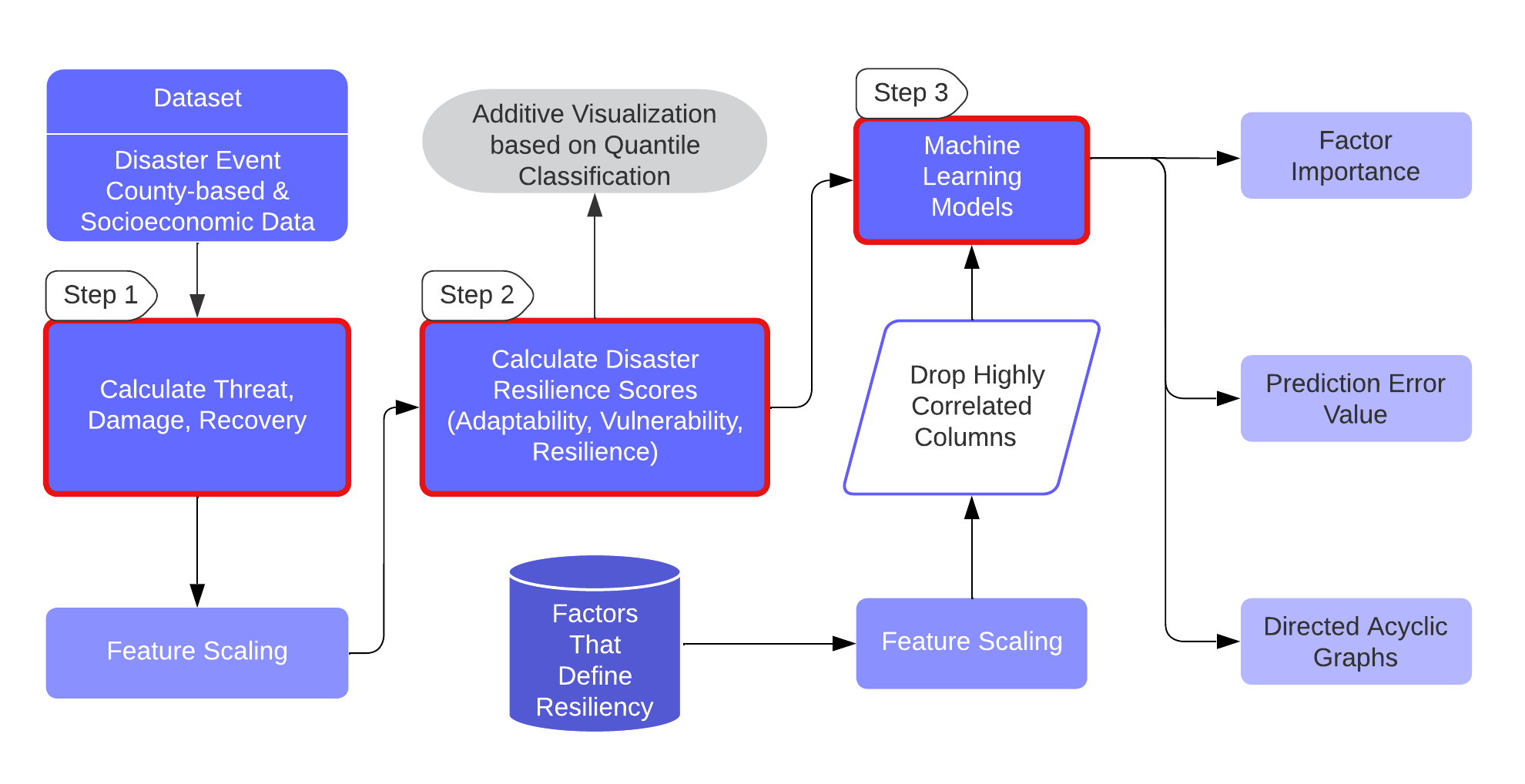
In formulating the CRIM model, we have based it on the fundamental framework of the RIM and addressed its limitations. Please refer to our paper for detailed breakdown of the enhancements and customizations. The workflow mainly operates using disaster event and socioeconomic datasets. In Step 1 and 2, it calculates resilience scores (adaptability, vulnerability, resilience) based on empirical parameters of hazard threat, damage, and recovery. In Step 3, CRIM uses machine learning regressors to learn the relationships between the resultant scores and socio-economic factors characterizing a community. These relationships are validated using a held-out test dataset. This not only confirms the reliability of the identified relationships but also ensures their generalizability.
Prerequisites to Model Implementation¶
This code has been tested to run properly for Python 3-0.9.0. Please make sure to choose that kernel so as not to run into any errors.
import warnings
from sklearn.preprocessing import MinMaxScaler
warnings.filterwarnings("ignore")
!pip install xgboost --quiet
All the Inputs¶
This section is only for entering filtering parameters from the whole dataset
Sample:
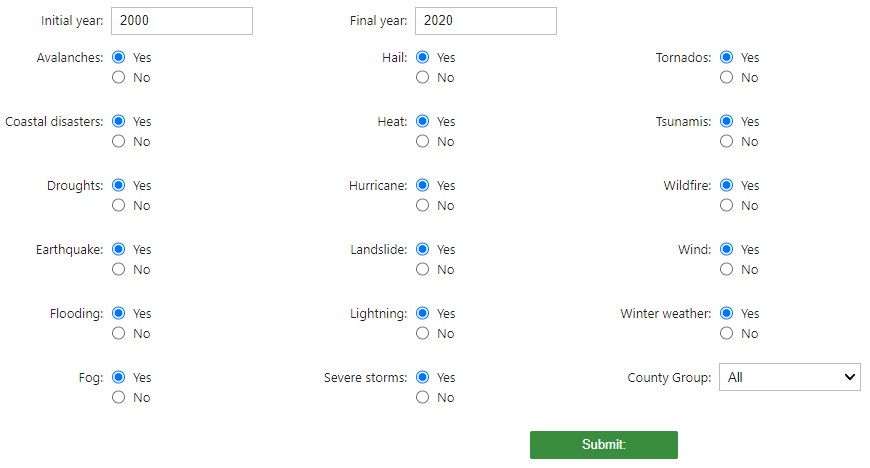
import preprocess as prep
widget_dict = prep.create_gui1()
prep.print1(widget_dict)
Data Pre-processing¶
fn = prep.process_data(widget_dict)
Three Empirical Factor Calculation¶
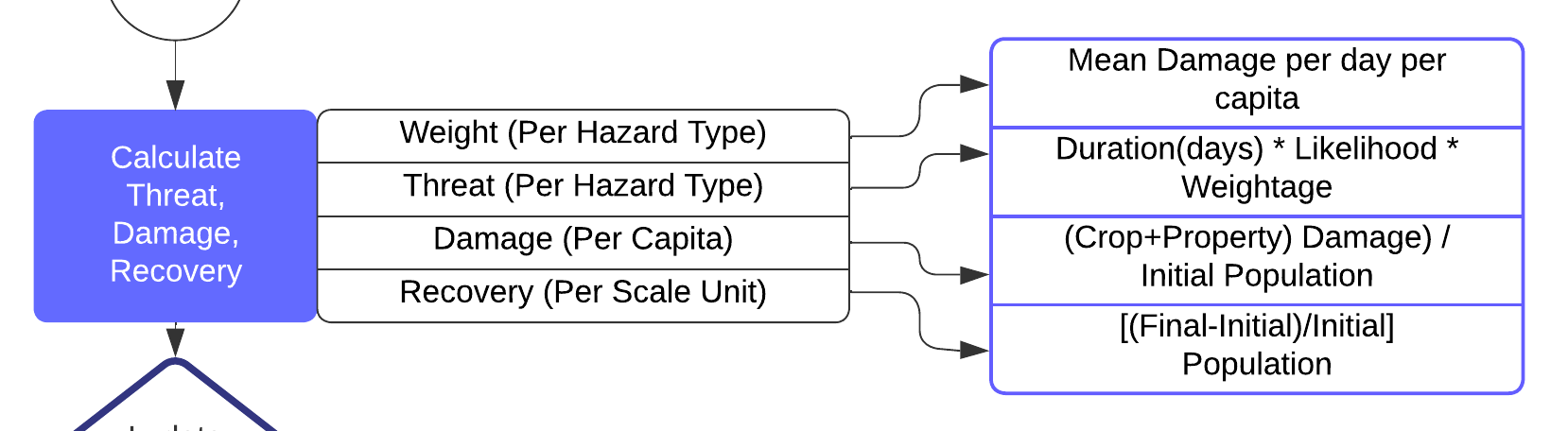
To realize these frameworks, we incorporated formulas aimed at quantifying the otherwise abstract concepts of vulnerability and adaptability. In the CRIM framework, we first compute the three empirical parameters: threat, damage, and recovery using the Comprehensive Hazard and Population data per year.
(Equation 1)
(Equation 2)
(Equation 3)
(Equation 4)
(Equation 5)
These equations are entirely modifiable as per requirements of the study
Equation 1:
The first component, duration, refers to the length of the historic hazard events, expressed in days. This variable recognizes that the impact of a hazard event typically increases with its duration. The second component is the likelihood, which quantifies the probability frequency distribution of hazard type per day (Equation 2). This factor acknowledges the inherent uncertainty in the occurrence of hazard events. The third component is the weight for each hazard event type. This weightage of each hazard event type is depicted as the mean damage caused per day per capita in a county. This factor recognizes that different hazard types can have different impacts based on its nature. For example, tornadoes might occur more frequently but cause less average damage than earthquakes. To calculate the weight (Equation 3), we assessed the individual damage data for each event to determine the mean damage per day per capita for each hazard event type.
Equation 4:
We derive a per capita estimate of the damage by dividing the sum of these damages by the pre-event initial population. Crop damage refers to the harm inflicted on agricultural produce by the disaster, which can impact local economies, particularly in areas heavily dependent on agriculture. Property damage pertains to the destruction of infrastructure (homes, businesses, public facilities) which has direct and immediate impact on urban residents' living conditions and livelihoods.
Equation 5:
the recovery variable gives a quantification of the community trying to return back to its original state before disaster. As population change is one prominent factor for quantifying how the community works despite disaster, i.e., if there has been migration to and from the community - this has been chosen as a Recovery factor. The increase in population has been calculated to be the recovery factor. A higher recovery rate for a county signifies an increase in population after the disaster events, indicating successful society rebuilding efforts.
edr_tot = prep.empfac(fn, widget_dict)
Disaster Resilience Indexes¶

Finally, the resilience indexes are calculated. The calculations and concepts are discussed in the following sections. For normalization technique we have opted for minmax scaling. MinMax Scaling rescales numeric features into a common range, typically 0 to 1, ensuring that no particular feature dominates due to its numeric range. The calculation involves subtracting the minimum value of a feature, then dividing by its range (maximum - minimum). This technique maintains the original distribution's shape but doesn't handle outliers well. In the new scale, the minimum value becomes 0, the maximum 1, and all other values fall proportionally within this range. It is particularly beneficial when the data does not follow a Gaussian distribution, which was the case with several of our parameters.
Users may modify the code to opt for z-score normalization too if the data follows a Gaussian distribution
Adaptability Calculation¶
Adaptability in disaster resilience refers to the ability of a community or system to adjust and respond effectively to changes or disruptions caused by a disaster. This includes the capacity to anticipate, absorb, and recover from the impacts of a disaster, and to learn from the experience in order to better prepare for future events. It is quantified using the Equation 6. Here, the difference is obtained after normalization as both the minuend and subtrahends are of different units.
(Equation 6)
Vulnerability Calculation¶
Vulnerability in disaster resilience refers to the susceptibility of a community or system to potential harm or damage caused by natural or human-made hazards. This can be influenced by various factors such as socioeconomic status, physical and environmental conditions, and access to resources and services. Reducing vulnerability is a crucial aspect of building resilience to disasters, as it enables communities to better withstand and recover from the impacts of disasters. We compute vulnerability as the normalized differential between damage and threat (equation 7). We express both these factors in the same units, and hence, obtain the difference before normalizing. The underlying principle contends that a community enduring equivalent destruction from infrequent disasters would be perceived as more vulnerable compared to a community exposed to more recurrent disasters.
(Equation 7)
Resilience Calculation¶
Resilience Score (equation 8) is a comprehensive measure of a community’s resilience to disasters. We interpret it as the relation between the adaptability and vulnerability of a community, and it is formulated as follows:
(Equation 8)
It implies that increasing a community's adaptability or reducing its vulnerability would improve the community's overall resilience score to disasters. These thus offer us insights into the dynamics of disaster impact and recovery.edr_tot,prgr = prep.disres(edr_tot)
Priori Group Visualization¶

For exploratory analysis purposes, we propose that the resultant scores are additive in nature. Under this assumption, we suggest that long-term resilience over the whole study period could be understood as the average of their yearly counterparts. It is a simplified perspective intended to provide an overarching view of the community's disaster resilience over a longer span. A quantile classification function in incorporated that transforms the continuous scores into four categories. This interactive map interface visualizes these resilience, vulnerability, and adaptability categories, in different choropleth layers, across different counties.
Sample:
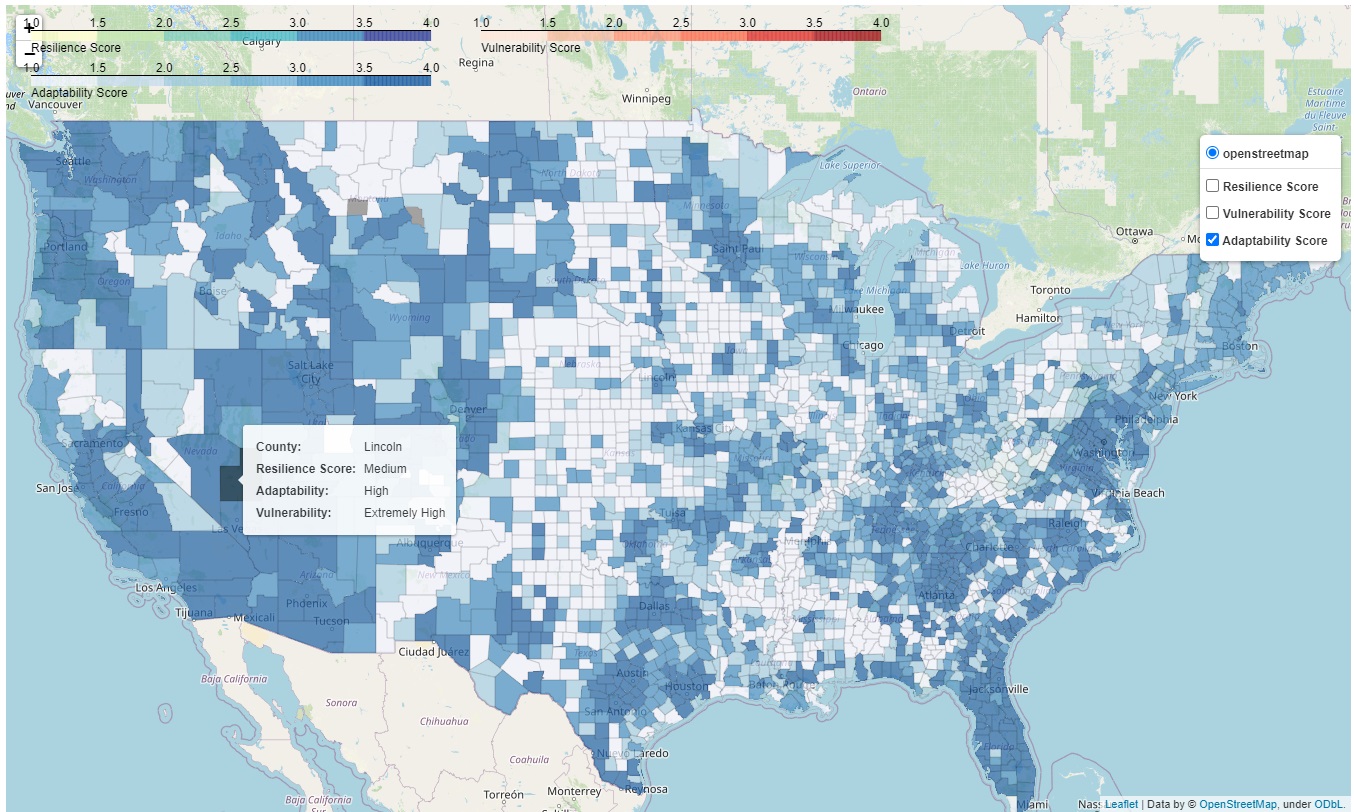
final_df = prep.gencpleth(prgr, "data/counties/geojson-counties-fips.json", widget_dict['ini'].value, widget_dict['fin'].value)